
数据库作为数字化用户的核心资产, 其迁移是一项复杂且重要的任务, 特别是在 VMware 平台替换及 IT 基础设施更新换代之时, 尤其需要保障数据库迁移过程的平稳、流畅。
数据库作为数字化用户的核心资产, 其迁移是一项复杂且重要的任务, 特别是在 VMware 平台替换及 IT 基础设施更新换代之时, 尤其需要保障数据库迁移过程的平稳、流畅。
深信服推出的数据库管理平台 (DMP) 是为关系型数据库量身打造的运维管理解决方案, 它整合了数据库日常运维所需的各项功能, 包括但不限于数据库的创建、实时监控、数据备份以及灾难恢复等。此外,DMP 还配备了先进的数据库迁移工具 DTS, 使企业能够将数据库从 VMware 平台或物理服务器无缝迁移至深信服的云计算环境中, 确保了迁移过程的高效率、安全性和可靠性。
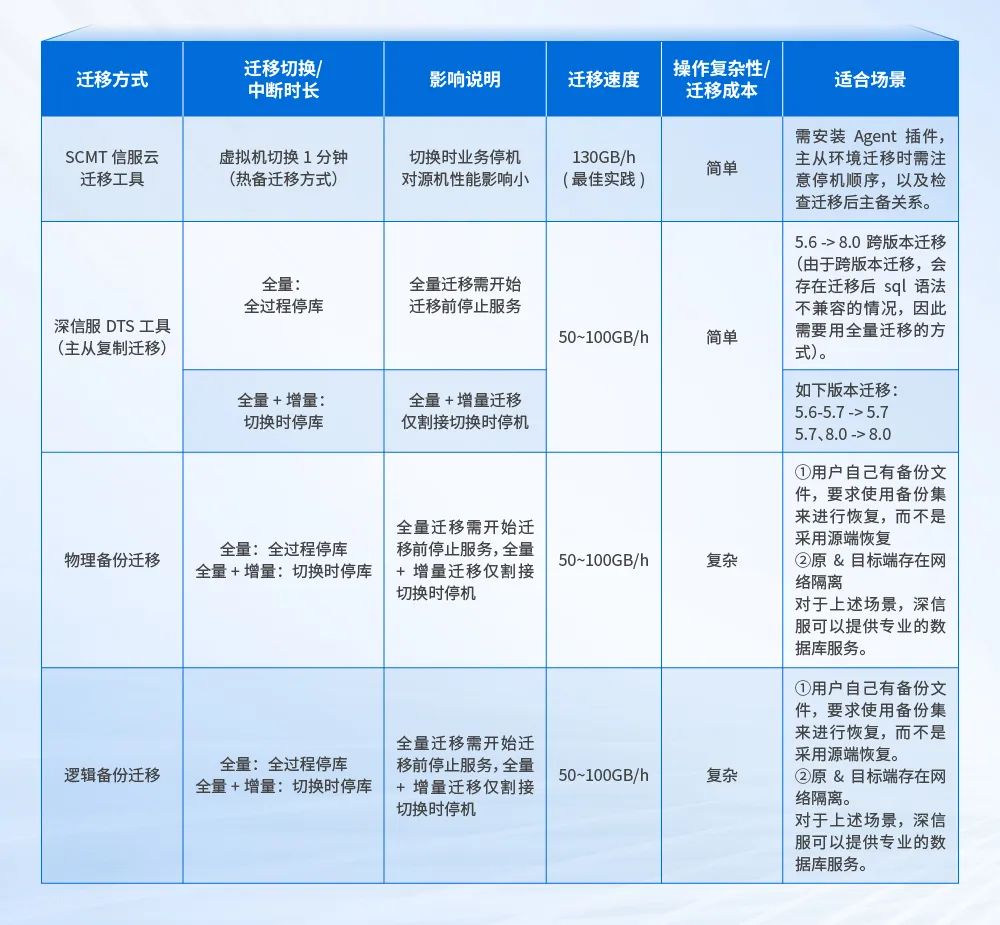
深信服为满足用户不同场景下的迁移需求, 提供丰富的 MySQL 数据库迁移方案:
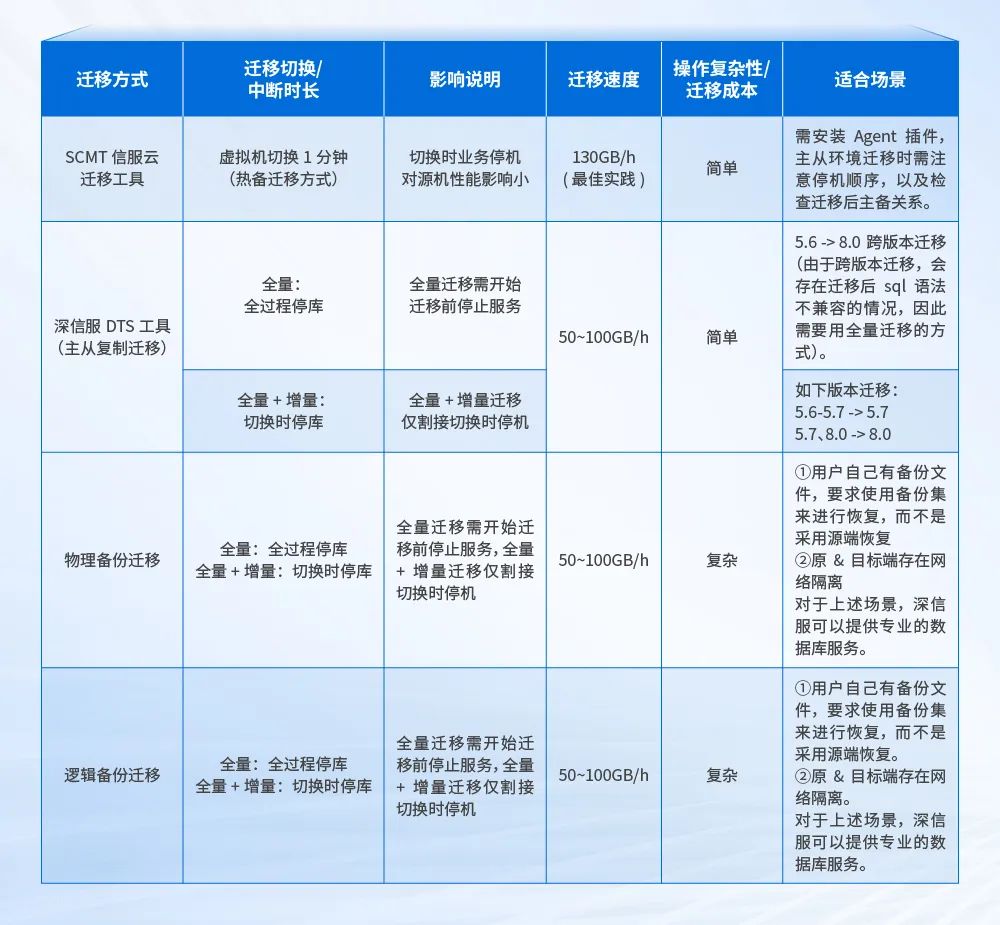
SCMT信服云迁移工具能够实现针对常见单机数据库的迁移, 支持点对点模式、热备模式等多种迁移方式, 操作简单, 对业务影响小。
DTS数据库迁移工具是深信服数据库管理平台 DMP 针对迁移场景开发的专用工具, 支持主从同步迁移, 通过配置 MySQL 的主从复制, 将数据从主库同步到从库, 然后进行角色切换。通常情况下采用全量+增量的迁移方式, 但是当 5.6 -> 8.0 跨版本迁移时, 由于会存在迁移后 sql 语法不兼容的情况, 因此需要采用全量迁移的方式。
物理备份/逻辑备份迁移, 面对 DMP 平台无法满足特定的迁移条件或要求时, 深信服将协调专业的数据库专家 DBA 来制定和执行定制化的物理备份/逻辑备份迁移方案。
本文重点介绍使用 DMP 的 DTS 工具对 MySQL 数据库进行全量加增量的数据迁移方式, 也是目前较为推荐的 MySQL 迁移方式。它利用 mydumper/myloader 逻辑备份恢复技术与 MySQL 主从复制原理, 通过与数据库内部组件的紧密协作, 实现数据的高效迁移。
迁移支持版本:
MySQL 5.6 → MySQL 8.0 全量迁移
MySQL 5.6-5.7 → MySQL 5.7 全量+增量迁移
MySQL 5.7、8.0 → MySQL 8.0 全量+增量迁移
迁移架构支持:
MySQL 单机 → MySQL 单机
MySQL 主从 → MySQL 主从
MySQL 单机 → MySQL 主从
MySQL 主从 → MySQL 单机
一、DTS 迁移技术原理
本文重点介绍使用 DMP 的 DTS 工具对 MySQL 数据库进行全量加增量的数据迁移方式, 也是目前较为推荐的 MySQL 迁移方式, 支持跨版本 (5.6-5.7)、支持跨平台迁移。
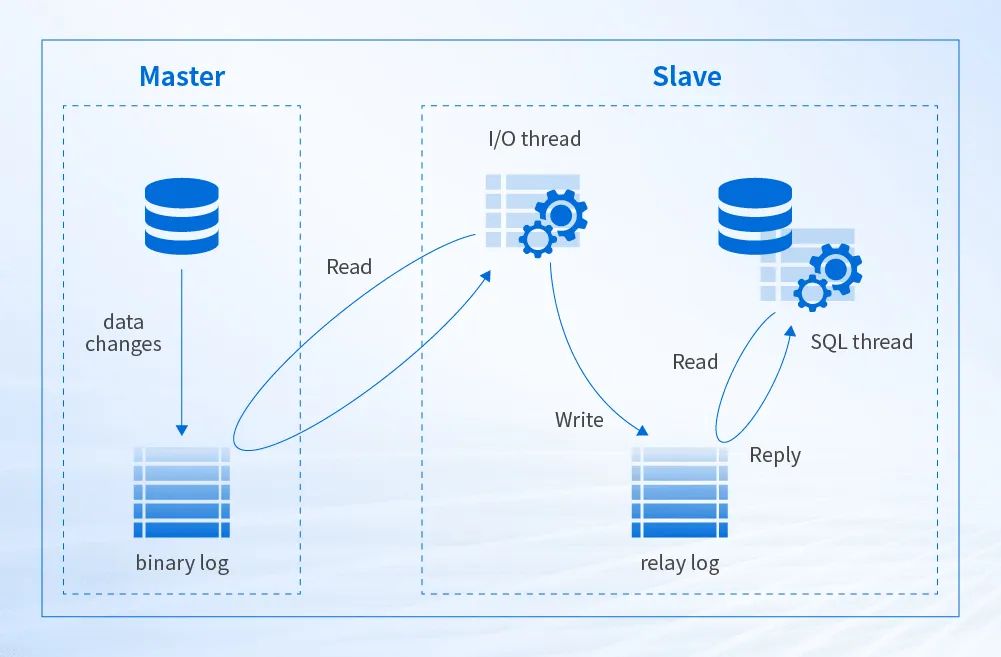
DMP 的 DTS 支持 mydumper + 主从复制方式迁移,mydumper 是一个用于 MySQL 的开源热备份工具, 它可以在不锁定表的情况下进行数据备份。使用 mydumper 和主从复制方式进行数据迁移的基本原理如下:
源、目标数据库初始化数据并建立主从关系;
从库会生成两个线程, 一个 I/O 线程, 一个 SQL 线程;
I/O 线程会去请求主库的 binlog, 并将得到的 binlog 写到本地的 relay-log(中继日志) 文件中;
主库会生成一个 log dump 线程, 用来给从库 I/O 线程传输 binlog;
SQL 线程, 会读取 relay-log 文件中的日志, 并解析成 sql 语句逐一执行。
深信服 DTS 数据迁移工具, 通过自动化和标准化的数据迁移策略, 大幅度降低操作难度并提升迁移效率。该工具通过直观的可视化界面, 为用户提供了一站式服务, 包括目标数据库的构建、迁移前的详尽检查、实时监控迁移过程以及高效切换控制。这种集成化的方法不仅简化了数据库的创建和性能优化, 还确保了用户能够精确地掌握并优化整个迁移流程, 以适应企业对数据库迁移的复杂和多变需求。
二、DTS 迁移注意事项
增量迁移阶段采用 GTID 模式的主从同步方式, 在迁移前源端需开启 BINLOG, 格式为 ROW, 且打开 GTID, 否则只能进行全量迁移, 不能做「全量+增量」模式迁移。
由于 mydumper 工具不支持迁移触发器 trigger, 如源端数据库有触发器且需要迁移到目标端数据库, 需在迁移完成后手动迁移触发器 trigger。
「全量迁移」类型任务, 在全量备份阶段, 源端会出现元数据锁, 阻塞 DDL 语句, 因此在此阶段源库无法执行 DDL 语句;同样的,「全量+增量迁移」类型任务, 在源库导出阶段期间, 源库也无法执行 DDL 语句。
MySQL 5.7 到 MySQL 8.0 跨版本「全量+增量迁移」类型任务时, 不支持源库执行语句:grant all privileges on *.* to user@'%' identified by 'password';。
「全量+增量迁移」类型任务迁移过程中, 无法同步源库的创建用户、修改用户权限操作, 所以在迁移过程中应避免增删改用户权限。
源端存在的空库 (database 下无任何数据库对象) 不会被迁移。
三、迁移过程及注意事项
(一)迁移时间评估
根据迁移的数据量和迁移过程中的操作, 整个迁移过程时间分布如下:
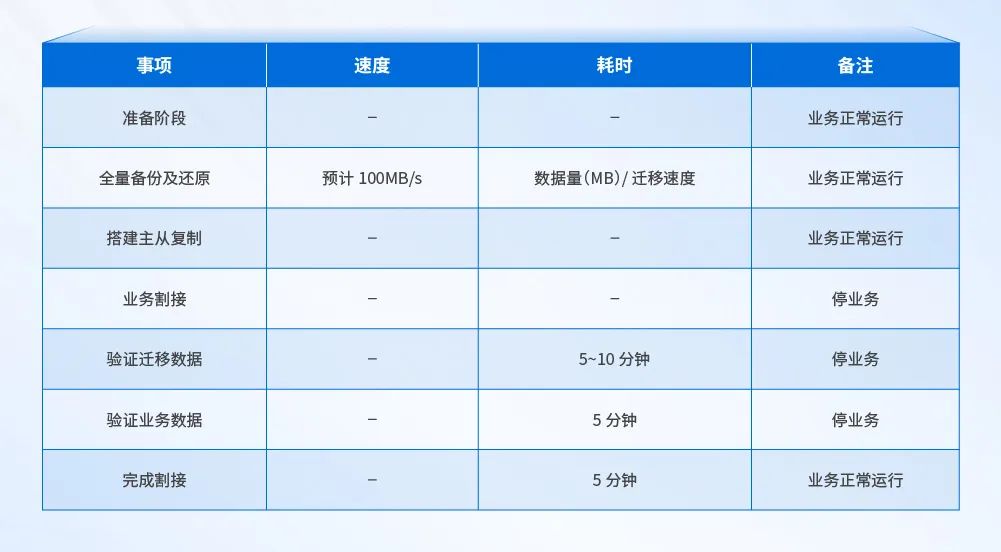
主从复制迁移步骤概览
(二)源库信息收集
在迁移前需要了解源环境和目标环境的硬件差异, 可以评估迁移的可行性和风险, 包括 CPU、内存、磁盘基础设施的配置和利用率, 基于硬件信息的收集, 可以合理规划迁移策略。
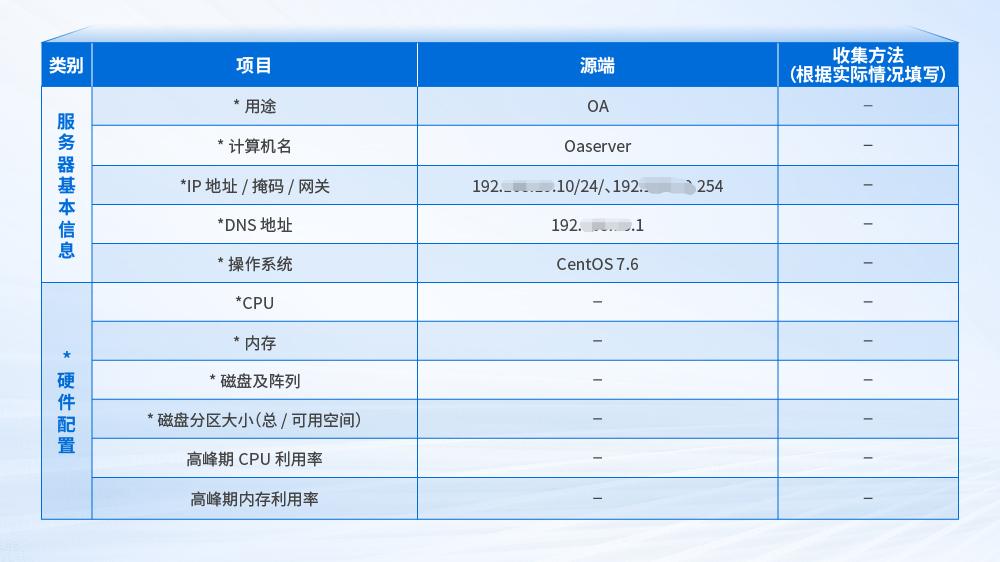
硬件信息收集示意
数据库信息收集是确保迁移过程中数据一致性的关键。通过收集数据库的版本、数据量和配置等信息, 可以制定详细的数据迁移计划和验证方案。在迁移过程中, 可以通过比较源数据库和目标数据库的数据差异来及时发现并解决问题, 确保数据的完整性和一致性。基于数据库信息的收集, 可以制定详细的迁移计划, 包括迁移的时间窗口、备份和恢复策略、迁移验证和回滚计划等, 减少迁移过程中的不确定性和风险, 确保迁移的顺利进行。
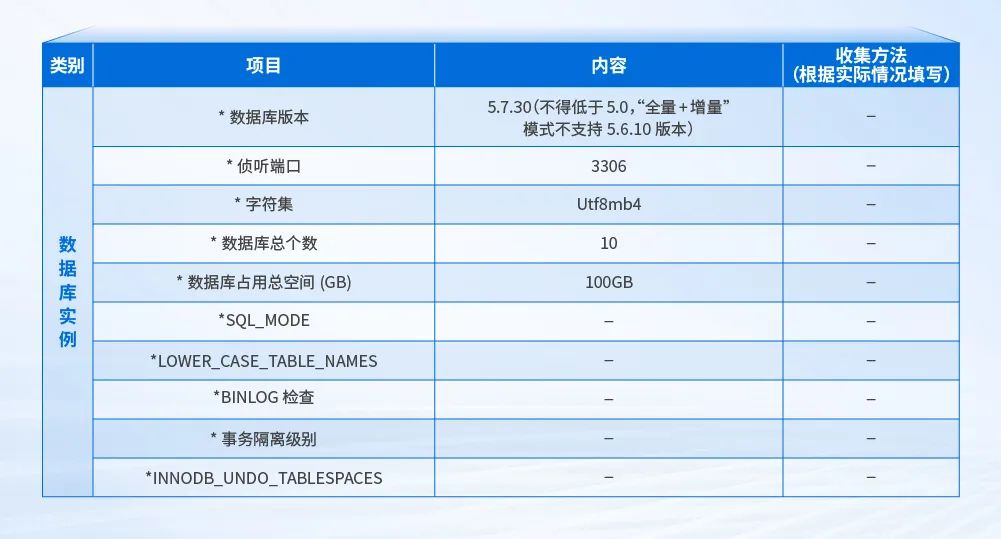
数据库信息收集示意
(三)目标数据库配置规划
核心业务系统数据库在迁移至深信服云计算平台时, 可能存在 CPU 和内存配置紧张, 或资源过剩的情况, 需要对原服务器进行配置变更评估。评估原则如下:
深信服平台物理主频建议要高于原服务器或者保持持平且不低于 2.0GHhz, 禁止云平台的性能低于原操作系统的主频。
合理的 CPU 和内存平均利用率在 30%-70% 之间, 业务高峰时也应保持在 80% 以内, 当原 VMware 平台使用率超过 70% 时, 考虑在深信服主机增加配置。
单实例数据库服务器配置建议 16C-32C, 如果 32C 还不能满足业务需求, 建议优化数据库, 排查慢 SQL 语句;或更改数据库架构为集群架构, 不建议再通过增加服务器配置来承载业务。
集群数据库服务器建议配置 16C-32C, 如果 32C 还不能满足业务需求, 建议优化数据库, 排查慢 SQL 语句;或为集群增加新的节点, 以承载更多的业务访问, 不建议再通过增加服务器配置来承载业务。
数据库内存在迁移上云时建议增加, 不建议降低, 随意降低数据库服务器内存可能会导致数据库无法启动。配置建议在 16G-64G 的区间, 具体配置需要通过专业的 DBA 进行计算, 迁移时不可随意更改数据库服务器内存配置。
源端数据库的磁盘使用率不高于 70% 的情况下, 迁移过来后可保持原状。如果源端磁盘使用率高于 70%, 在扩容时需考虑到未来 3-5 年的业务增量进行测算。
单实例数据库创建完成后只能修改数据盘/日志盘的大小, 不能扩容数量。例如源数据库配置了 4 块 1T 磁盘, 后面扩盘时只能扩大小, 例如扩容到 4 块 2T 磁盘。
集群数据库服务, 只能增加数据盘/日志盘的数量, 不建议扩容大小。例如源数据库配置了 4 块 1T 磁盘, 后面扩盘只能扩数量, 例如扩容到 8 块 1T。
如果是 P2V 迁移的系统, 磁盘大小配置和原物理的保持一致, 数据文件和日志文件所在的磁盘为提高 IO 的吞吐, 建议将磁盘进行预分配。
(四)切换与回退设计
在正式执行数据迁移之前, 建议将源库克隆出测试库进行一次迁移测试。这一步骤至关重要, 因为不同的物理环境可能会导致迁移所需的时间出现差异。通过测试迁移, 不仅可以评估迁移过程中可能遇到的时间问题, 而且可以验证迁移方案的可行性和有效性。此外, 迁移测试还有助于识别潜在的问题和风险, 从而在正式迁移之前采取相应的预防措施。
数据库切换前必须确认业务系统已完全停止对数据库的访问和写入。在进行切换时,DMP 允许用户选择是否在切换过程中自动关闭源数据库。通常情况下, 为了确保业务顺利上线, 我们会在业务系统上线前连接源数据库进行数据验证, 此时无需自动关闭源数据库。然而, 如果无法确保源数据库的数据写入操作已完全停止, 或者在切换过程中担心源数据有变化, 那么在进行切换时选择自动关闭源数据库将是一个更为稳妥的措施。
数据库迁移完成后, 应更新业务系统连接地址, 以确保通过目标数据库的服务 IP 进行访问。在网络环境中, 如果存在访问控制策略, 应在迁移前调整策略, 以避免影响业务访问。如果是白名单模式, 应允许最底层的全禁止策略;如果是黑名单模式, 则应在最上层添加允许所有策略。待业务系统完全迁移后, 再重新启用相应的访问控制策略。
在数据库成功迁移并经过业务验证之后, 建议立即进行全面备份。这样, 在目标数据库遇到无法迅速解决的问题时, 可以迅速恢复到迁移后的状态。同时, 建议保留源数据库的运行状态 (但不要关闭服务器), 以便在新平台出现问题时, 能够迅速切换回源数据库继续提供服务。
在数据库迁移和切换过程中, 必须确保源数据库环境的完整性不受破坏。如果在切换过程中遇到异常, 或者在业务验证阶段发现问题, 应立即联系深信服产品线专家和数据库管理员 (DBA) 寻求支持。在允许的时间范围内, 应优先诊断问题, 调整迁移参数或系统配置, 以迅速恢复迁移流程。
在数据库迁移过程中, 如果遇到无法在停机窗口期内迅速解决的异常问题, 应立即回退到源数据库环境。在回退之前, 需要分析失败的原因, 并根据分析结果重新制定迁移计划。在决定回退时, 要确保在迁移过程中没有新的业务数据写入到新数据库, 以避免在回退过程中丢失最新的业务数据。
如切换后发现业务有问题, 不得不回切至源数据库, 可以利用割接后的增量日志, 生成 SQL 文件, 与用户相关人员沟通后, 可以在源端执行增量还原。
四、迁移过程说明
(一)创建迁移任务
此处以全量+增量迁移任务, 整库迁移的方式为例, 以下是具体的操作步骤:
使用 DTS 迁移工具新建迁移任务, 迁移前请确保源库已开启 binlog, 并开启 GTID,GTID(Global Transaction ID, 全局事务 ID), 用来强化数据库的主备一致性、故障恢复, 以及容错能力。用于取代过去传统的主从复制 (即:基于 binlog 和 position 的复制)。若迁移任务为全量迁移情况, 则无须开启此参数。
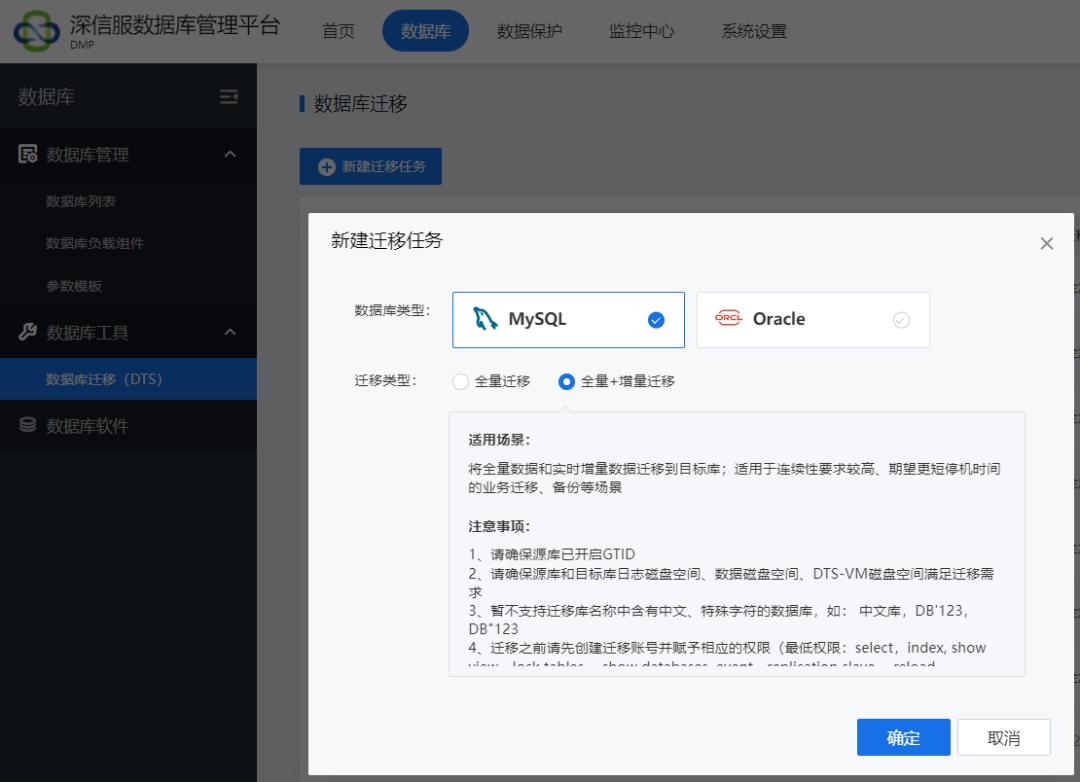
(二)数据迁移过程
在确认源数据库和目标数据库的配置之后, 接下来需要为数据库迁移设置实例参数、迁移服务 (DTS-VM, 用于执行迁移任务的工具, 包括数据导出与导入、日志抽取与重放等;不会占用迁移配额, 迁移完成后将自动删除该云主机并释放对应的资源) 配置。当启动 DTS 工具执行迁移任务时, 它将自动进行一系列预检查, 包括验证源和目标数据库之间的连通性、用户权限、数据库架构、数据库版本兼容性、字符集、存储引擎、系统信息、迁移数据量等。预检查中发现的「不通过项」将直接影响迁移任务的执行, 必须在迁移前解决;而「告警项」则通常不会妨碍迁移过程, 可以在人工审核后选择忽略, 继续执行迁移任务。
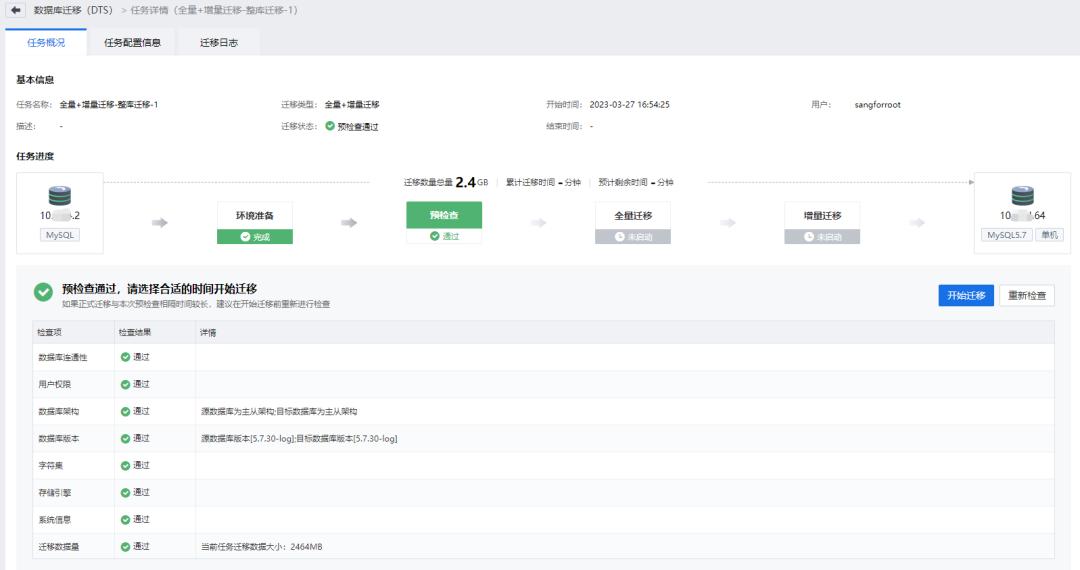
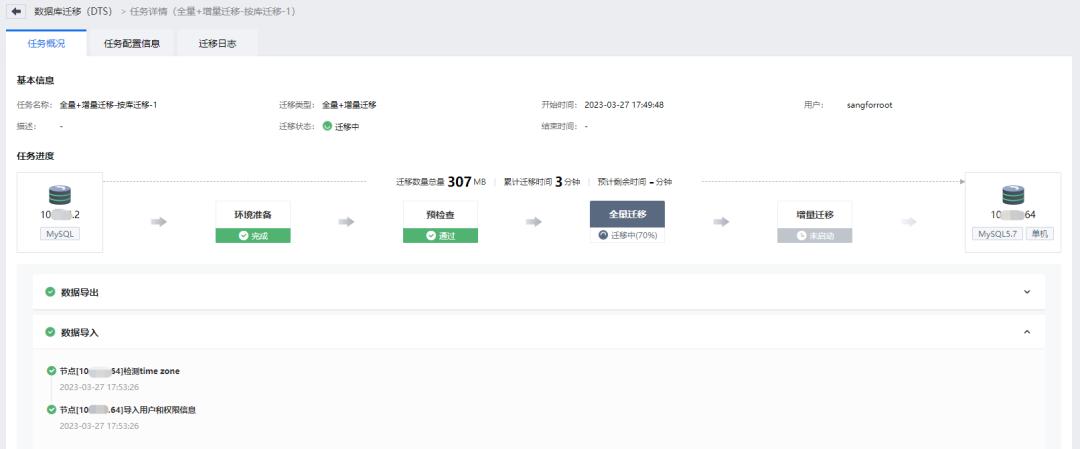
首先进行全量迁移过程,DTS 会完成以下动作:源端数据库全量导出、目标端数据库全量恢复。全量迁移过程中对源库业务不会产生影响, 建议在业务低峰期执行, 或者减少并发数并时刻观察对生产业务产生的影响。所有 DTS 操作过程都会添加时间戳显示在前端, 运维人员可实时监控整个迁移过程。
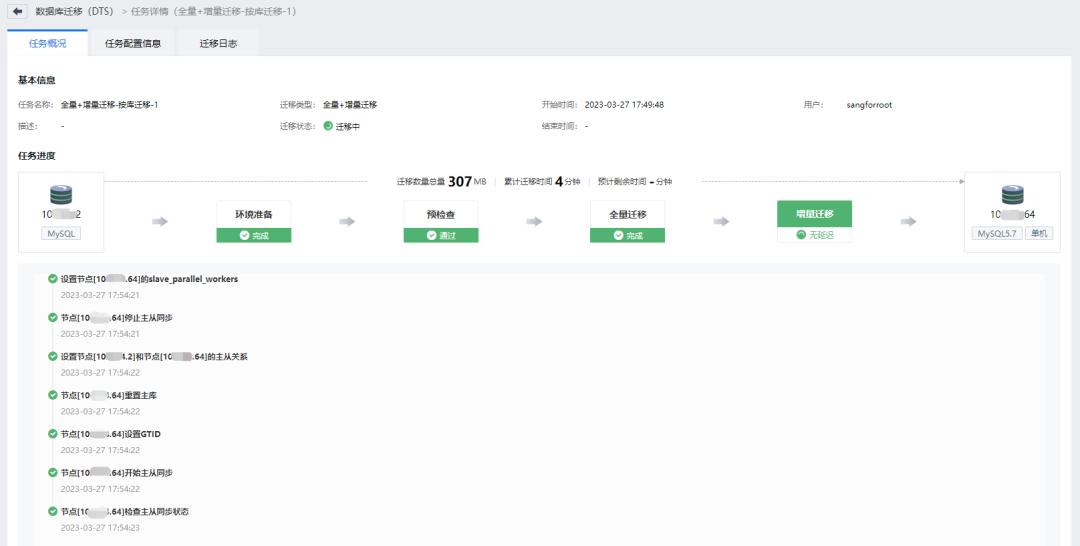
在首次全量备份成功完成后,DTS 系统将进入持续性的增量同步阶段。增量同步的核心任务是实时进行主从同步。增量迁移过程中,DTS 会完成以下动作:设置源&目标端主从关系, 重置主库、设置 GTID、主从同步、检查主从同步状态。在此过程中, 目标端会持续获取源端 binlog 日志文件信息, 并利用 SQL Thread 进行回放, 从而实现增量同步。这种增量同步操作不会对源数据库的业务运行造成任何影响。
根据深信服在用户端的迁移实践经验, 使用千兆迁移网络时, 全量数据迁移的理想速率为 30MB/s, 这使得每小时大约能够迁移 100GB 的数据。然而, 迁移速率受多种因素影响, 包括源数据库的数据结构、物理网络条件以及带宽限制。因此, 实际迁移速度需要根据具体情况进行评估和调整。
(三)停库切换过程
数据库迁移切换过程需要停库中断业务, 在确定了停机时间后, 应向各业务部门发布维护通知, 停止业务和应用对源数据库的访问, 避免产生数据丢失等意外情况产生。同时需协调业务人员、运维人员、应用厂商、深信服厂商等多方工作人员协助保障迁移切换和业务验证工作。
全量迁移任务待任务执行完成后, 即数据库迁移完毕, 完成切换, 业务可访问新实例进行业务验证;全量+增量迁移任务, 需手动执行割接, 割接完成后, 业务访问新实例进行业务验证。
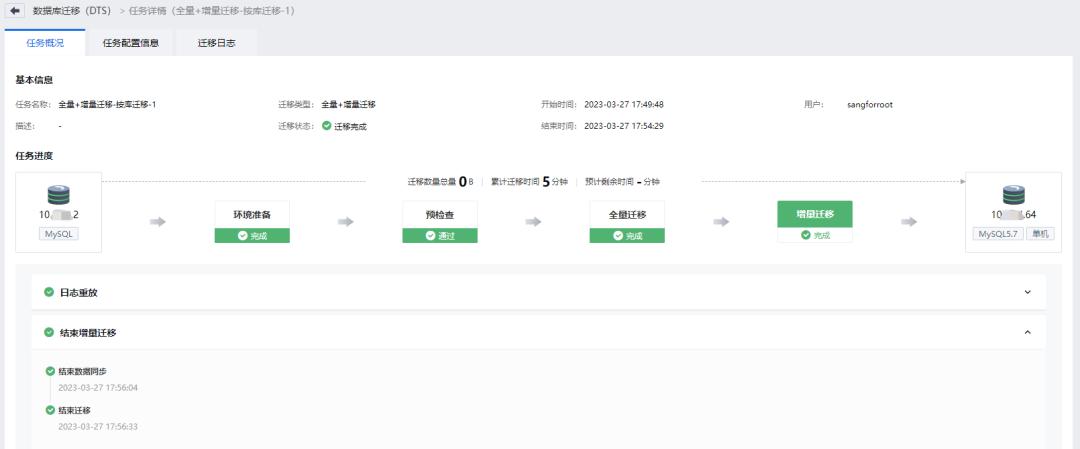
在数据库切换流程完全执行完毕后, 所有源端数据将被成功迁移至目标端数据库。此时, 可以对源端和目标端数据库进行连接, 以进行数据的检查和校验, 确保数据库状态的一致性。完成数据校验后, 应协调业务团队成员进行业务访问测试。这一测试过程至关重要, 它确保了从业务角度来看, 系统能够正常工作, 满足业务需求。

五、附录
(一)准备迁移用户
建议使用数据库全权限用户如 root@'%'(和 root@'localhost'不是同一个用户) 进行迁移。如果源端不能使用全权限数据库用户执行迁移, 需在源端创建迁移用户。创建用户及赋权语句如下:
注意:迁移用户的密码中特殊字符仅支持:()`~!@#$^&*_-+=|{}[]:<>.?/。
MySQL5.6、5.7、8.0 全量迁移用户权限
mysql> create user dtsuser@'%' identified with mysql_native_password by 'dtspassword';
mysql> grant select,event,show view,lock tables,reload on *.* to dtsuser@'%';
MySQL5.6、5.7、8.0 全量+增量迁移用户权限
mysql> create user dtsuser@'%' identified with mysql_native_password by 'dtspassword';
mysql> grant select,event,show view,lock tables,replication slave,replication client,reload on *.* to dtsuser@'%';
(二)在线开启GTID
GTID(Global Transaction ID, 全局事务 ID), 用来强化数据库的主备一致性、故障恢复, 以及容错能力。用于取代过去传统的主从复制 (即:基于 binlog 和 position 的复制)。
若迁移任务为全量+增量迁移情况, 则必须开启此参数。
以下操作主从均需要执行:
1.开启GTID预检查
mysql> set @@global.enforce_gtid_consistency=WARN;
开启此参数后, 需观察 MySQL 错误日志, 若有违反 GTID 规则的事务会有告警, 应及时调整。
设置告警后, 部分操作会被告警, 请注意调整业务或关闭 GTID, 例如:
(1) 执行CREATE TABLE ... SELECT语句:
(MySQL8.0.21 以后对于支持原子 DDL 的存储引擎, 例如 InnoDB 引擎, 支持该操作)
例如:
create table t1 select * from sbtest3;
查看错误日志:
2023-06-19T11:44:05.956128+08:00 82810 [Warning] Statement violates GTID consistency: CREATE TABLE ... SELECT.
修改:
create table t1 like sbtest3;
insert into t1 select * from sbtest3;
(2) 在事务中执行CREATE TEMPORARY TABLE or DROP TEMPORARY TABLE语句:
例如:
begin;
select * from sbtest3 for update;
create temporary table t2(id int);
查看错误日志:
2023-06-19T11:52:42.254719+08:00 82810 [Warning] Statement violates GTID consistency: CREATE TEMPORARY TABLE and DROP TEMPORARY TABLE can only be executed outside transactional context. These statements are also not allowed in a function or trigger because functions and triggers are also considered to be multi-statement transactions.
修改:
避免在事务中执行创建或删除临时表。
2.开启GTID校验
mysql> set @@global.enforce_gtid_consistency=ON;
这一步一旦执行, 违反 GTID 的操作都会被拒绝, 比如 create table as select, 所以上一步 WARN 阶段确保无违反 GTID 规则的事务。
3.开启GTID_MODE
mysql> set @@global.gtid_mode=OFF_PERMISSIVE;
观察 ongoing_anonymous_transaction_count 值:
mysql> show global status like '%ongoing_anonymous_transaction_count%';
确认已经没有匿名的事物, 建议多观察一段时间, 如果不为 0, 强行修改可能会导致数据丢失。
4.GTID_MODE设置为ON_PERMISSIVE
mysql> set @@global.gtid_mode=ON_PERMISSIVE;
5.GTID_MODE设置为ON
mysql> set @@global.gtid_mode=ON;
6.从库执行 (若源端为单机, 忽略此步骤)
mysql> stop slave;
mysql> change master to master_auto_position=1;
mysql> start slave;
mysql> show slave status\G
这一步, 所有老的 relay log 都清理掉了, 新 relay log 包含的全是 GTID 操作 Event。
7.修改配置文件 (永久生效)
若未添加至配置文件, 则数据库重启后参数失效,GTID 关闭。
主从均执行
# vim /etc/my.cnf
在 mysqld 下添加以下内容
[mysqld]
gtid_mode=ON
enforce_gtid_consistency=ON
(三)修改BINLOG_FORMAT
BINLOG_FORMAT是MySQL中的一个参数, 用于指定二进制日志文件的格式。MySQL 的复制方式与 binlog(二进制日志文件) 格式一一对应。
mysql复制主要有三种方式:
基于 SQL 语句的复制 (statement-based replication, SBR);
基于行的复制 (row-based replication, RBR);
混合模式复制 (mixed-based replication, MBR)。
对应的,binlog 的格式也有三种:STATEMENT,ROW,MIXED。
修改 BINLOG_FORMAT 的步骤如下:
1.先在从库执行、再去主库执行
mysql> set global binlog_format=ROW;
2.修改配置文件 (主从都修改)
# vim /etc/my.cnf
在 mysqld 下添加以下内容
[mysqld]
binlog_format=ROW
(四)手动迁移触发器trigger
1.检查询命令默认业务触发器没有创建在系统数据库中, 所以排除系统数据库sys、mysql、information_schema、performance_schema。
mysql> select TRIGGER_SCHEMA,count(*) as tiggers_cnt from information_schema.`TRIGGERS` where TRIGGER_SCHEMA not in ('sys','mysql','information_schema','performance_schema') group by TRIGGER_SCHEMA;
如上命令执行后有结果, 如图所示, 源端业务数据库 sakila、test 分别有 6、1 个触发器, 则需要迁移。
如上命令执行后查不到数据, 则表示业务数据库中无触发器需要迁移。
2.方法一:(推荐)
1. 在目标端数据库后台执行如下命令导出源端触发器。注意:在-B 参数后面添加需要导出的业务数据库 (即上一章节查询出来的 TRIGGER_SCHEMA) 的名字, 如有多个使用空格分隔。
-h:源端数据库 ip 地址, 如「10.5.54.66」。
-P:源端数据库端口号, 如「3306」。
-u:源端数据库迁移账号, 如「root」
-p:源端数据库迁移账号密码, 如「Admin-123」。
# mysqldump -h10.5.54.66 -P3306 -uroot -pAdmin-123 --single-transaction --set-gtid-purged=OFF --default-character-set=utf8mb4 --add-drop-trigger --no-create-db=true --no-create-info=true --no-data=true -B sakila test > ./tri.sql

注意:导出源端触发器用户需要有「trigger」权限。
(2) 导入到目标端数据库。
# mysql -uroot -pQwer@123 -S/run/sock/mysql.sock < ./tri.sql

(3) 检查触发器是否迁移成功
在目标端执行命令查询, 参考「Part.5 附录中第 4 节 手动迁移触发器 trigger 的检查源端是否存在触发器」。
3.方法二
1. 在目标端用 root 用户登录 RDS 主节点, 访问源端数据库导出业务数据库触发器 DDL 语句。
# cd
# rm -rf trigdump.sql
# touch trigdump.sql
# mysql -h10.5.54.66 -P3306 -uroot -pAdmin-123 <<'EOF'
tee trigdump.sql
SELECT
CONCAT("DROP TRIGGER IF EXISTS `",
TRIGGER_SCHEMA,
"`.`",
TRIGGER_NAME,
"`;\nDELIMITER ;;\nCREATE TRIGGER `",
TRIGGER_SCHEMA,
"`.`",
TRIGGER_NAME,
"` ",
ACTION_TIMING,
" ",
EVENT_MANIPULATION,
" ON `",
EVENT_OBJECT_SCHEMA,
"`.`",
EVENT_OBJECT_TABLE,
"` FOR EACH ROW\n",
ACTION_STATEMENT,
";;\nDELIMITER ;") AS TRIG
FROM
information_schema.TRIGGERS
WHERE
TRIGGER_SCHEMA IN ('sakila','test')\G
notee
exit
EOF
# sed -i '/^*/d' trigdump.sql
# sed -i 's/TRIG: //' trigdump.sql
# echo "COMMIT;" >> trigdump.sql
(2) 导入触发器至目标端主节点
# mysql -uroot -p -S/run/sock/mysql.sock < trigdump.sql
(3) 检查触发器是否迁移成功
在目标端执行命令查询, 参考「Part.5 附录中第 4 节 手动迁移触发器 trigger 的检查源端是否存在触发器」。
来源:互联网


