

随着 GPU 计算能力与 HBM 带宽的提升,运力瓶颈对 AI 硬件能力提升的限制逐步显现。以超节点、大集群为代表的算力基础设施发展方向,正推动行业竞争转向「系统级效率」层面,加快行业运力突破。
随着 GPU 计算能力与 HBM 带宽的提升,运力瓶颈对 AI 硬件能力提升的限制逐步显现。以超节点、大集群为代表的算力基础设施发展方向,正推动行业竞争转向「系统级效率」层面,加快行业运力突破。
10 月 15 日,开源证券发布研报表示,当下国产算力厂商发展如火如荼,存力方面也逐步在 HBM 取得进展,运力的发展将成为下一个国产化攻坚的重点。国产 Scale-up/Scale-out 硬件商业化提速,建议关注 AI 运力产业投资机遇。
同时,申万宏源此前发布研报认为,超节点等技术产业化,将重塑算力产业链分工,催生服务器整合、光通信增量及液冷渗透提升等投资机会。联想集团等在算力基础设施领域具备多环节能力的厂商,正在产业链分工中迎来更多维度的市场红利。
从「单卡性能」到「系统级效率」
从技术上看,AI 硬件能力主要由算力、存力与运力三方面构成。其中,算力以 GPU 性能和数量决定,存力使用贴近 GPU 的超高带宽 HBM 缓存是当前主流方案,运力则分为 Scale-up、Scale-out 等场景,分别对应节点内、节点间与数据中心间的高速通信和数据传输能力。
过去几年,AI 行业更多关注芯片算力的提升,先进制程、单卡性能成为行业争夺话语权的焦点。但随着 GPT-4 等大模型参数规模不断扩大至万亿级别,同时单卡功耗持续飙升,传统算力架构已难以满足高效、低耗、大规模协同的 AI 训练需求。
在此背景下,AI 基础设施的发展范式正在重新定义。东方证券表示,晶圆制造工艺升级和先进封装满足了个人电脑、智能手机等产品的性能升级,但仍可能跟不上 AI 算力需求的增长和 AI 服务器性能的快速发展需求,系统组装正成为性能提升的新驱动力。申万宏源亦表示,在大模型参数呈爆炸式增长的当下,算力需求正从单点向系统级整合加速转变。这一趋势下,Scale-up 与 Scale-out 成为算力扩容的两大核心维度。

其中,Scale-up 突破传统单服务器、单机柜限制,提升单节点算力,进入"超节点"时代。9 月 18 日,华为在全联接大会 2025 上发布 Cloud Matrix384 超节点产品 Atlas950 超节点卡,相比英伟达将在明年下半年上市的 NVL144,Atlas 950 超节点卡的规模是其 56.8 倍,总算力是其 6.7 倍,内存容量是其 15 倍,互联带宽是其 62 倍,在各方面均呈领先,成为 Scale-up 的代表之一。
Scale-out 则主要用于超大规模 AI 集群中大量节点之间的横向互联。中国信通院近日发布的《算力中心创新融资研究报告(2025 年)》显示,当前智算中心已步入万卡及十万卡甚至更高级别。例如 7 月 22 日,OpenAI 宣布将与 Oracle 合作,将在建的 Stargate Al 数据中心总容量提升至超过 5GW,运行超过 200 万颗芯片。xAI 亦计划将超级计算工厂 Colossus 的 GPU 数量从 20 万块增加到 100 万块。国内企业也在积极建设万卡集群,中国移动黑龙江有限公司的超万卡国产化智算中心项目总投资达 42 亿元,腾讯、阿里、字节跳动、科大讯飞等企业也发布了超万卡集群。
开源证券表示,超节点成为趋势,其通过提升单节点计算能力,大幅带动了 Scale-up 相关硬件需求;超大规模 AI 集群的建设,则带动 Scale-out 相关硬件需求,运力市场规模迅速提升。
应用 Scale-up/Scale-out 技术的可扩展服务器亦随之加速渗透。根据国际数据公司(IDC)数据,2024 年中国高端超级可扩展服务器市场规模已达到约 386 亿元,同比增长 21.7%。IDC 预测,2025 年至 2029 年期间,中国高端超级可扩展服务器市场将以 24.3% 的年均复合增长率(CAGR)持续扩张,到 2029 年有望突破 1120 亿元。
算力基础设施领域的科技企业,正在这一市场机遇中加紧布局。联想集团副总裁、中国基础设施业务群总经理陈振宽表示:「最近超节点非常热,这个属于 Scale-up 的范畴,我们已开始投入资源来开发超节点技术和产品,重点就是对互联网络技术的研发;在 Scale-out 的集群上,我们重点投入推理场景下的 PD 分离技术,助力算力集群的 Token 生产效率。」
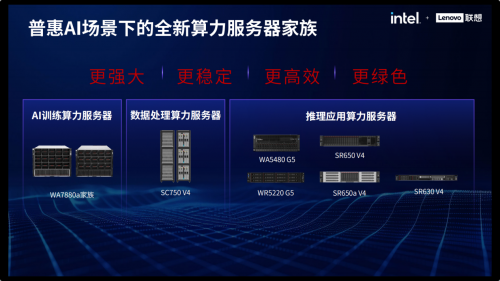
作为国内较早进入服务器领域的企业,联想集团几年前就提出了高性能、高可靠、高可扩展、低能耗(「三高一低」)的服务器设计理念。在今年 5 月于上海举办的 2025 联想创新科技大会(Tech World)上,联想集团对数据处理、AI 训练、推理应用三大服务器产品家族全线升级,并推出了一系列服务器新品。这些服务器新品均采用英特尔最新一代处理器——英特尔®至强®6,较上一代处理器配备更多内核和更快内存,每个内核均内置 Al 加速功能,性能更强。同时,它们分别面向不同的 AI 应用场景进行了针对性优化,以充分释放这些服务器的算力潜能。
华龙证券认为,中美 AI 竞争正从「单卡性能」走向「系统级效率」竞争,中国正在用集群建设+开源生态+工程化交付的方式完成 AI 基建方面的弯道超车。申万宏源亦表示,单机柜算力密度提升与多机柜全互联架构成为行业竞争焦点,把握技术路径演变下的产业链机会,聚焦硬件互联与场景适配双线布局,建议关注数据中心产业链、AI 芯片与服务器供应商等标的。华为、联想集团等科技企业,成为这一轮市场逻辑转换中的重要受益者。
技术升级进一步重塑市场格局
在 AI 基础设施发展范式重构背景下,可扩展服务器实现快速渗透的同时,亦面临异构计算与 AI 加速芯片集成、液冷散热与高密度部署等技术升级挑战,并由此进一步重塑市场格局。
以液冷散热技术与高密度部署技术为例。民生证券指出,超节点速率大幅提升的同时,由于包括华为 Cloud Matrix384、英伟达 GB200 NVL72 在内的超节点单机柜功耗普遍突破 100KW,因此在算力密度指数级增加的情况下,机柜的温控和电源系统将面临挑战。而当 Atlas950 超节点采用全液冷模式时,其互联带宽速率和算力速率均有望迎来大幅提升。
液冷散热技术与高密度部署方案作为支撑未来算力基础设施的关键技术路径,近年来在中国市场呈现出加速演进与规模化落地的态势。据中国信息通信研究院测算,2024 年我国智算中心液冷市场规模达 184 亿元,较 2023 年同比增长 66.1%;预计未来经过 5 年增长,到 2029 年将达到约 1300 亿元。

科技企业高度重视服务器技术升级,以更好迎接 AI 算力扩容的时代机遇。如联想集团在 2024 年 10 月 16 日刚刚发布搭载最新一代联想「海神」温水水冷系统的联想 SD650V3 液冷服务器,在仅仅半年之后,便又于今年 5 月举办的 2025 联想创新科技大会(Tech World)上,发布"飞鱼"仿生散热设计和"双循环"相变浸没制冷系统两大液冷技术创新成果。
其中,"飞鱼"仿生散热设计通过模拟鱼在水中游动的姿态,降低热阻与流阻,成功突破散热器性能瓶颈,最大支持功耗提升 20%,帮助用户以最小的代价解决下一代 600W 芯片的散热难题。
"双循环"相变浸没制冷系统则是联想集团与清华大学联合研发的液冷技术,通过创新的外接单相换热器设计,实现相变腔体温度的精准控制和沸腾换热效能的显著提升,散热能力较传统方案翻倍提升,系统 PUE 可低至 1.035,达业界领先水平。
至此,联想集团完成冷板式、单相浸没式、相变浸没式三大主流技术路线的液冷技术布局,通过对不同场景的全面覆盖,满足更多 AI 基础设施的技术要求。这既展现出联想集团强大的技术能力,也宣示了公司在抢抓 AI 基础设施市场机遇上的强烈雄心。
在异构计算方面,联想集团也在在全面落地去年 5 大差异化技术的基础上,通过集成持续创新的四大异构智算技术,将万全异构智算平台升级至 3.0 版,助力本地基础设施算力效率实现新的突破。比如,AI 推理加速算法集,可帮助 AI 推理性能提升 5-10 倍;AI 编译优化器,使得训练和推理计算成本至少降低 15%;AI 训推慢节点故障预测与自愈系统,实现了百卡秒级、千卡分钟级、万卡十分钟级故障自愈;专家并行通信算法,则将推理延迟降低了至少 3 倍。
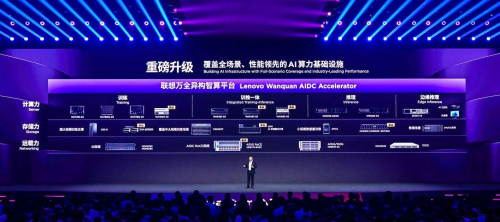
在国家级高质量 AI 集群场景中,联想集团与东数西算第一大智算枢纽紧密合作,在千卡训练场景中将 MFU 从 30% 提升至 60%;针对模型本地部署的企业 AI 基础设施场景,全速运转满血版 DeepSeek R1 模型极限吞吐量已经超越 12000 Tokens/s,凸显出联想万全异构智算平台 3.0 的差异化优势。而则背后,则是集团从芯片设计、存储网络到算法层面的全链条软硬协同创新能力。
海通国际认为,人工智能仍是未来主线,算力供给端竞争焦点向互联优化转移,算力侧的自主可控、高带宽互联、密集封装、更高能效系统是未来方向,继续看好计算机板块。联想集团等企业从可扩展服务器硬件渗透,到液冷散热、异构计算等技术升级的全面聚焦式布局,有望使其更好抢抓市场扩容与格局重塑的双重机遇,实现企业价值的最大化扩张。
来源:互联网


