
近期,Soul App AI 团队 (Soul AI Lab) 已开源实时数字人生成模型 SoulX-FlashTalk。
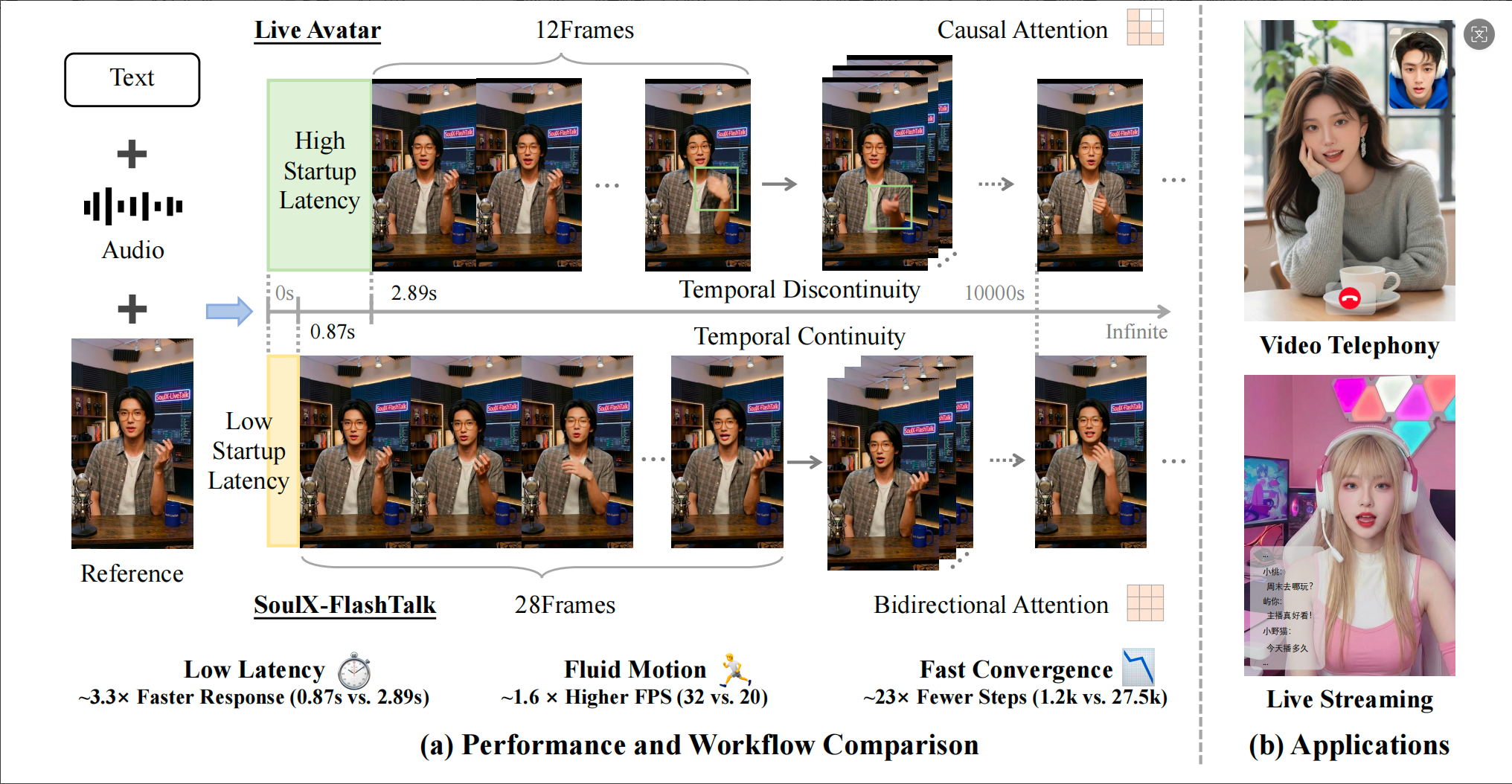
近期,Soul App AI 团队 (Soul AI Lab) 已开源实时数字人生成模型 SoulX-FlashTalk。这是首个能够实现 0.87s 亚秒级超低延时、32fps 高帧率, 并支持超长视频稳定生成的 14B 数字人模型。
在持续建设 AI 能力的过程中,Soul 团队始终致力于通过技术创新实现更沉浸、多元的交互体验。此次开源新模型, 除了在速度、效果、延迟和保真度上表现出色, 更重要的是, 为行业提供了切实可应用的业务解决方案, 推动大参数量实时生成式数字人迈入可具体商用落地阶段。
SoulX-FlashTalk 亮点:
四大关键指标, 重塑实时互动体验
0.87s 亚秒级延时, 即时交互
在实时视频交互中, 延迟是决定用户体验的核心。SoulX-FlashTalk 凭借全栈加速引擎的极致优化, 成功将首帧视频输出的延时降至 0.87s 亚秒级。
•「零延迟」即时反馈: 首次让 14B 级大模型数字人具备了即时反应能力, 彻底消除了传统大模型生成的「滞后感」。
•全场景交互: 无论是视频通话中的即时对答、直播间弹幕的秒级互动, 还是智能客服的实时响应, 均能实现自然、流畅的深度对话。
32fps 高帧率, 重新定义「流畅」
尽管搭载了 14B 参数量的超大 DiT 模型,SoulX-FlashTalk 的推理吞吐量仍高达 32 FPS。
•超越行业标准:远超直播所需的 25 FPS 实时标准, 确保每一帧画面都丝滑顺畅。
•大模型, 高性能:证明了 140 亿参数大模型在经过深度加速优化后, 依然可以拥有极佳的运行效率。
超长视频稳定清晰生成, 告别画面「崩坏」
数字人视频最怕在生成中出现人物面部不一致或显著画质下降的问题。SoulX-FlashTalk 凭借独家的自纠正双向蒸馏技术, 解决了这一痛点:
•无感纠错, 画质无损:引入多步回溯自纠正机制, 模拟长序列生成的误差传播并进行实时修正, 就像为 AI 装上了「实时校准器」, 主动恢复受损特征。
•超长视频, 稳定生成: 不同于传统的单向依赖,SoulX-FlashTalk 完全保留了双向注意力机制, 让每一帧生成都能同时参考过去与隐含的未来上下文, 从根本上压制身份漂移, 这意味着在超长直播中, 主播的口型、面部细节和背景环境将始终保持一致, 不会出现模糊或变形。
全身动作交互:不只是「口型对齐」
SoulX-FlashTalk 突破了传统数字人仅能实现面部「对口型」的局限, 带来了更加真实自然的全身肢体动态表现。
•全身肢体动态合成: 不同于仅对脸部进行局部重绘的方案,SoulX-FlashTalk 支持受音频驱动的全身动作生成, 产生真实自然的人体动态。
•高精细手部表现: 基于 14B DiT 的强大建模能力, 系统能够有效消除手部畸形与运动模糊, 精准呈现结构清晰、纹理锐利的手部动作细节。
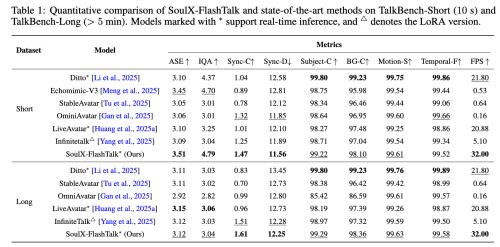
•灵动而不失稳定: 在追求大幅度动态表现力的同时, 系统依然维持了极高的身份一致性 (Subject-C 达 99.22), 实现了动作灵活性与画面稳定性的完美平衡。
核心方案:
双向蒸馏+多步回溯自纠正机制
在行业中, 传统数字人生成方案大多面临画面生成时间长、延迟高、生成效果差、效果不稳定、保真度低等问题。
在这样的背景下,SoulX-FlashTalk 正式开源, 为了平衡生成质量与推理速度, 团队采用了两阶段训练策略:
第一阶段:延迟感知时空适配 (Latency-Aware Spatiotemporal Adaptation), 结合动态长宽比分桶策略进行微调, 使模型适应较低的分辨率和更短的帧序列;
第二阶段:自纠正双向蒸馏 (Self-Correcting Bidirectional Distillation)。利用 DMD 框架压缩采样步数并移除无分类器引导 (CFG), 实现加速;多步回溯自纠正机制, 通过 autoregressively 合成连续分块 (最多 K 个 chunks), 显式模拟长视频生成的误差传播;随机截断策略, 在训练中在第 k(< K) 个分块数进行反向传播, 实现高效且无偏的显存友好优化。
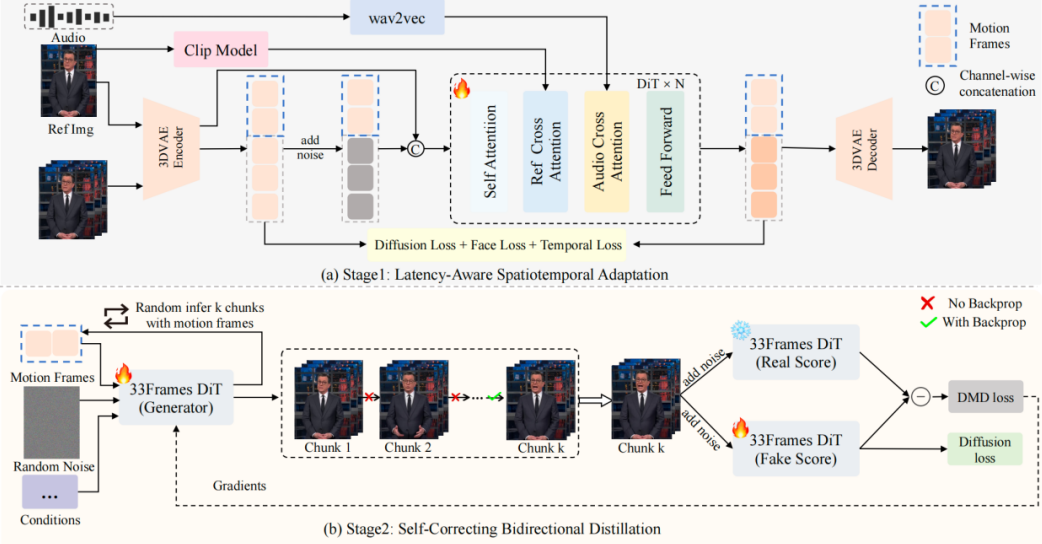
训练流程示意图
同时, 团队进行实时推理加速系统优化, 针对 8-H800 节点设计的全栈加速引擎实现了亚秒级延迟, 包括了
•混合序列并行 (Hybrid Sequence Parallelism):整合 Ulysses 和 Ring Attention, 使单步推理速度提升约 5 倍算子级优化:采用针对 Hopper 架构优化的 FlashAttention3, 通过异步执行进一步减少 20% 的延迟。
•3D VAE 并行化:引入空间切片并行解码策略, 实现 VAE 处理的 5 倍加速。
•整链优化:通过 torch.compile 实现全流程图融合与内存优化。
值得注意的是, 在 Soul AI 团队发布的技术报告中指出, 传统的单向 (Unidirectional) 模型在处理全局时间结构时存在约束, 容易导致时间不一致和身份漂移。因此, 团队完全保留双向注意力机制 (All-to-All 交互), 使模型能同时利用过去与隐含的未来上下文, 显著提升了生成的一致性与细节质量。
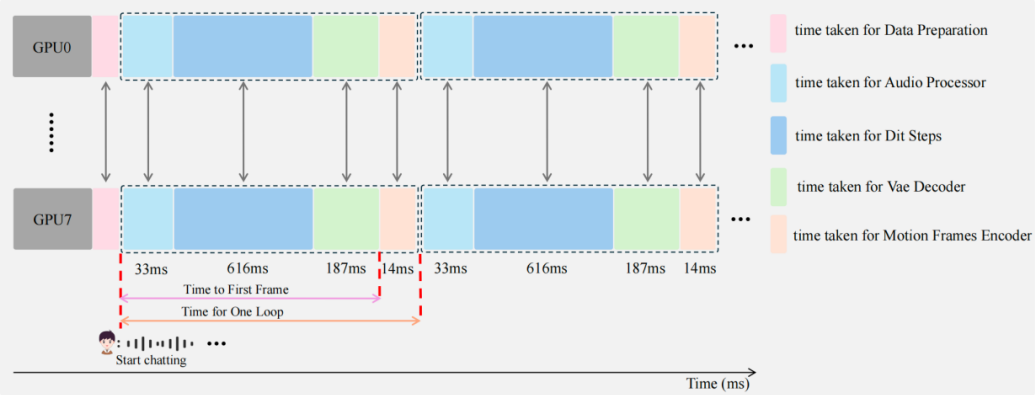
SoulX-FlashTalk 推理架构流程图
AI+实时体验
赋能行业多元业务场景
从模型表现来看, 通过在 TalkBench-Short 和 TalkBench-Long 数据集上的定量对比, 展示了 SoulX-FlashTalk 在视觉质量、同步精度及生成速度上的全面领先:
在短视频评测中, 它以 3.51 的 ASE 和 4.79 的 IQA 刷新了视觉保真度记录, 并以 1.47 的 Sync-C 分数表现出最优的口型同步精准度;在 5 分钟以上的长视频生成中, 系统凭借双向蒸馏策略有效抑制了同步漂移, 取得了 1.61 的 Sync-C 优异成绩;此外, 作为 14B 参数规模的大模型, 它在长短视频任务中均维持了 32 FPS 的高吞吐量, 不仅远超 25 FPS 的实时性基准, 更在推理效率上显著优于行业同类主流模型。
依托模型优越的性能表现, 开源后,SoulX-FlashTalk 将有机会在多领域、行业实际落地, 创造更多价值。例如, 在电商领域打造 7×24 小时 AI 直播间, 特别是, 此前传统的数字人直播长时间运行后常会出现嘴型对不上或画质模糊的问题, 而 SoulX-FlashTalk 可以支持全天候的流畅视频直播, 即便是在高强度的实时互动中 (如回复弹幕), 也能保持如同真人出镜的高保真画质, 极大降低直播成本。
此外, 在短视频制作、AI 教育、多元互动场景 NPC 交互、AI 客服等方向, 模型也提供了高质量、可落地、可接入业务系统的解决方案。
对 Soul 而言,SoulX-FlashTalk 的发布也意味着团队进入了开源新阶段。去年 10 月底,Soul AI 团队开源语音合成模型 SoulX-Podcast, 在发布后快速登顶开源社区平台 HuggingFace TTS(Text To Speech) 趋势榜, 目前该模型在 GitHub 上收获了超 3100 星标。
接下来, 在聚焦语音对话合成、视觉交互等核心交互能力的提升, 为用户带来更加沉浸、智能且富有温度的交互体验的过程中, 以持续推进开源工作为契机,Soul 将积极与全球开发者携手, 共建生态, 为推动「AI +社交」方向前沿能力建设贡献力量。
来源:互联网


