

在实时数字人赛道, 开发者们曾长期面临一个困扰:追求高画质就需要具备昂贵的 H800 集群, 追求低成本就得忍受「面瘫」和画面崩坏。
在实时数字人赛道, 开发者们曾长期面临一个困扰:追求高画质就需要具备昂贵的 H800 集群, 追求低成本就得忍受「面瘫」和画面崩坏。
为解决这一问题, 继开源 14B 的实时数字人生成模型 SoulX-FlashTalk 之后, 近日,Soul App AI 团队 (Soul AI Lab) 推出了 SoulX-FlashHead。这款 1.3B 参数的轻量化模型, 能够在单张消费级显卡 ( RTX 4090 ) 上跑出 96FPS 的工业级速度, 同时实现高质量画质, 为行业提供新的实时数字人方案。

SoulX-FlashHead 核心亮点:
不仅是实时, 更是「算力自由」
在消费级显卡上,SoulX-FlashHead 的表现:
·Lite 版本 (高速率):单卡 4090 推理帧率可达 96FPS, 仅需 6.4G 显存, 最高支持 3 路并发, 让实时数字人模型真正走到了消费级终端上。
·Pro 版本 (高画质):单卡 5090 推理帧率 16.8FPS, 双卡可实时 (25fps+),FID(视觉质量指标) 和 Lip-sync(唇形一致指标) 在 benchmark 上达到了 SOTA, 甚至超过了更大参数量的模型, 解决了「小模型没好画质」的行业痛点。
原理介绍
如何让 1.3B 模型「以小博大」?SoulX-FlashHead 创新引入了:
训练「先知」:双向蒸馏机制 (Oracle-Guided Distillation)
长视频生成的「身份漂移」一直是行业痛点。SoulX-FlashHead 引入了「上帝视角」教师模型, 利用 Ground Truth 作为先知锚点进行强约束。
效果: 像给模型装了校准器, 无论视频多长, 人物特征始终稳定。
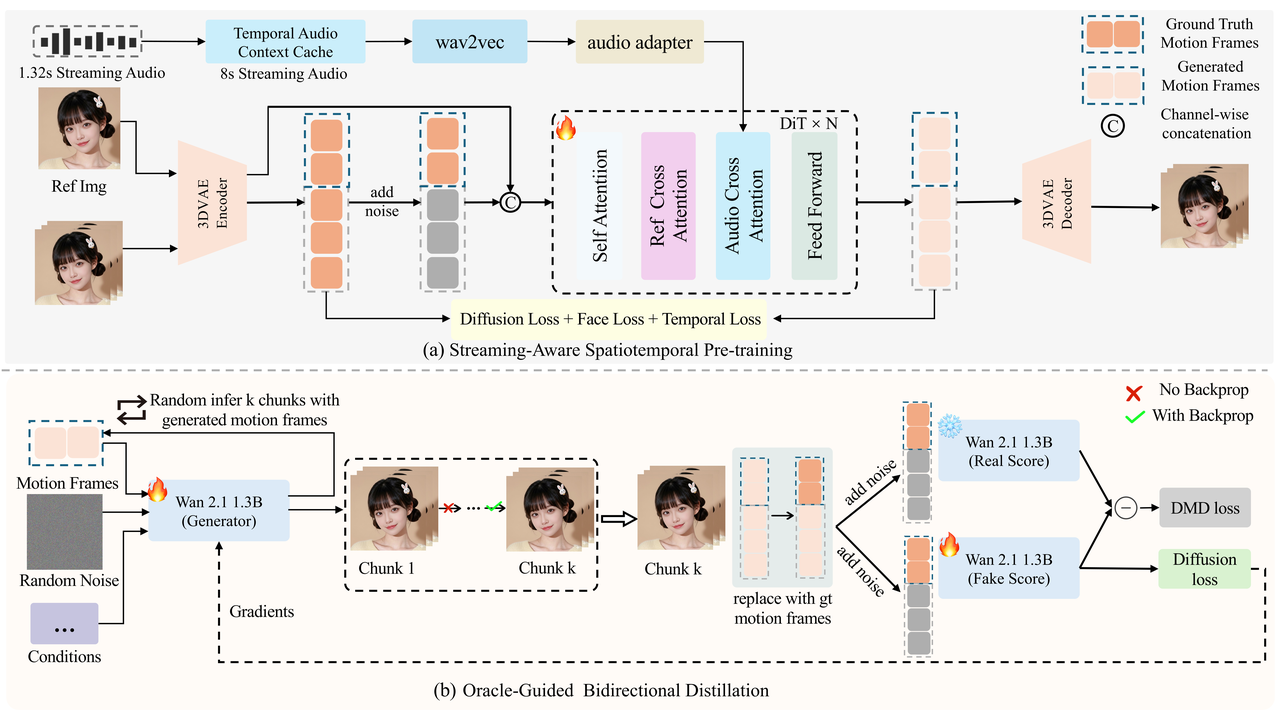
8 秒记忆:时序音频上下文缓存 (TACC)
流式生成中, 音频切片太短会导致口型抖动。
创新: 强制模型缓存 8 秒 历史音频特征, 补偿上下文缺失。
体验: 解决「嘴瓢」和「对不上号」问题, 开播即进入理想状态。
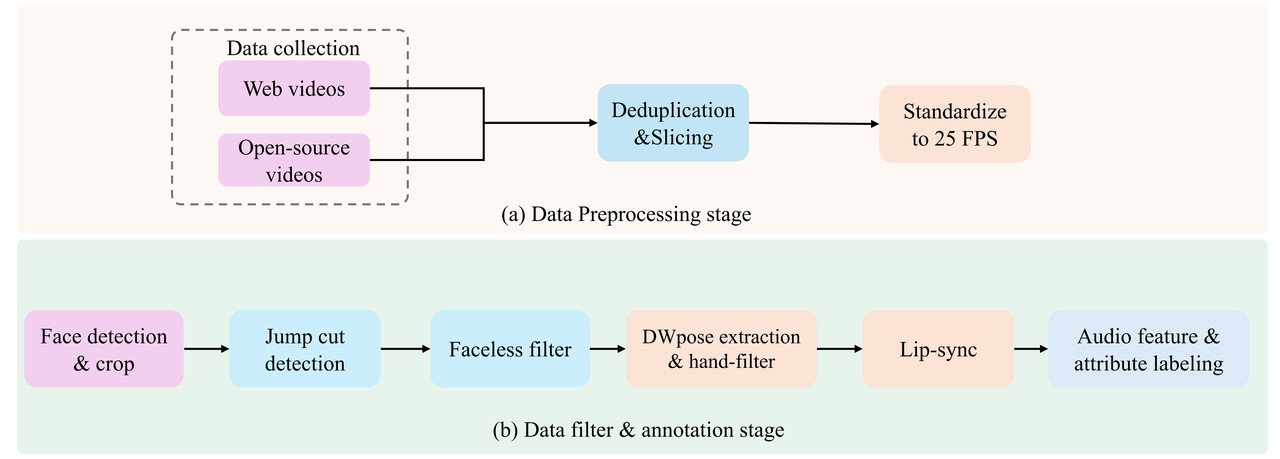
高质量数据底座:自研 VividHead 数据集
从 10,000+ 小时素材中精炼出 782 小时高质量音画数据:
严苛筛选: 经过切分、DWpose 关键点、唇形一致分数过滤等多个处理步骤, 为模型提供了最纯净的「养料」。
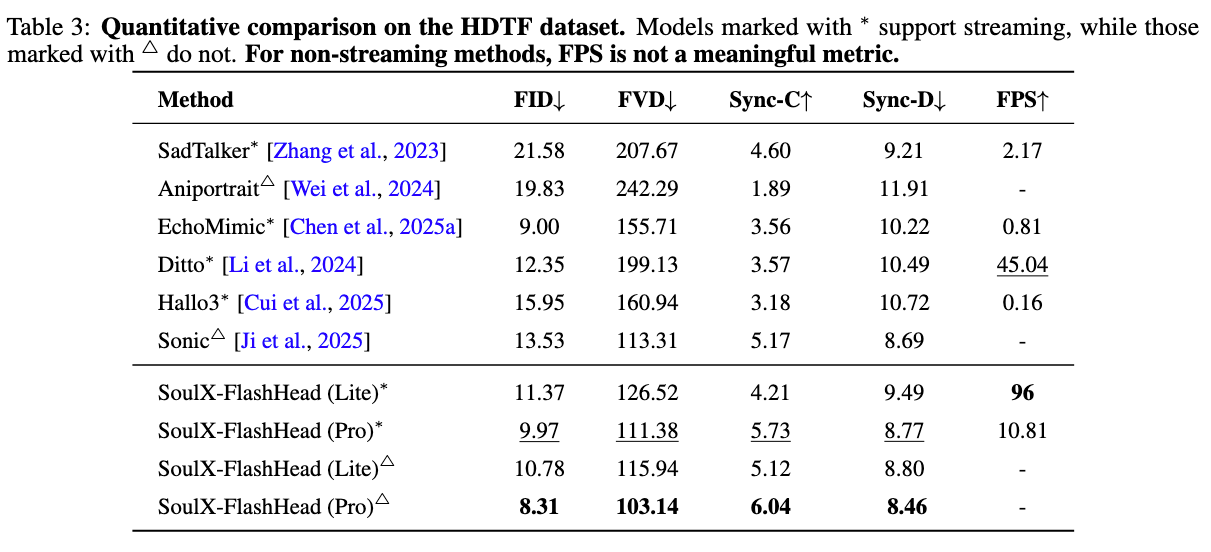
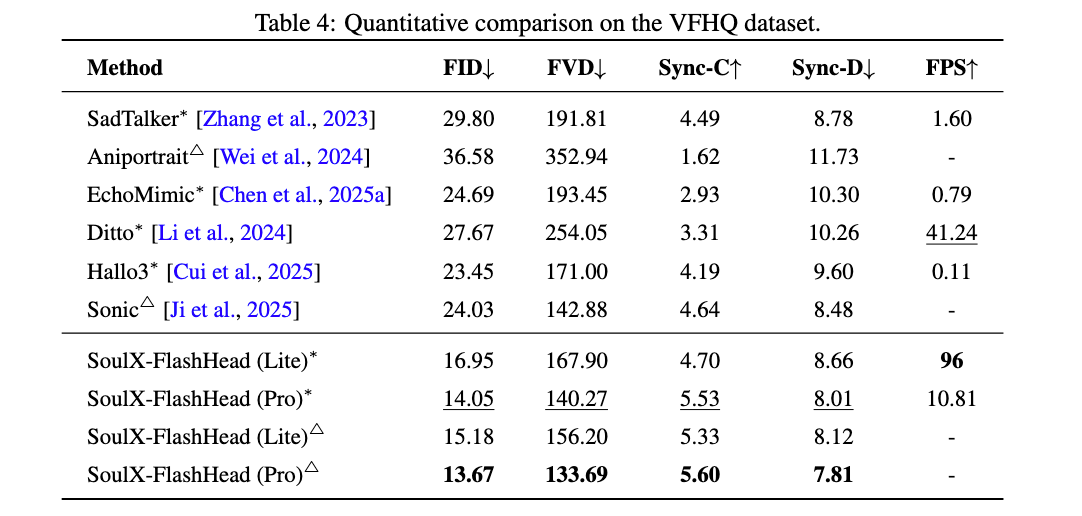
客观表现
在 HDTF 与 VFHQ 两大权威数据集的实测中,SoulX-FlashHead 展现了出色的表现:
画质新标杆:在高清视频 (HDTF) 评测中,Pro 版本以 8.31 (FID) 和 103.14 (FVD) 的成绩刷新纪录, 视觉细腻度超过 一些「大参数」模型。
口型精准捕捉:面对野外复杂场景 (VFHQ), 凭借独创的「时序音频上下文缓存」策略, 其 Sync-C 得分高达 5.60, 大幅领先此前相关工作, 解决对不上口型的尴尬。
速度「快」:仅凭 1.3B 的轻量化体量,Lite 版本在单张 RTX 4090 上跑出了 96 FPS 的吞吐量。这不仅是实时基准 (25 FPS) 的 近 4 倍, 推理效率更是行业同类主流模型的 100 倍以上。
应用场景:
「人人可用」的数字人技术
今年 1 月,Soul AI Lab 开源了实时数字人生成模型 SoulX-FlashTalk, 能够实现 0.87s 亚秒级超低延时、32FPS 高帧率, 并支持超长视频稳定生成。
对比 SoulX-FlashTalk,SoulX-FlashHead 的价值在于, 将高保真技术进一步从「算力机房」解放到了「个人工作站」, 让更广泛的场景应用成为可能:
·7x24h 矩阵直播:个人主播用一台游戏 PC, 即可搭建高保真电商直播间。
·游戏 NPC 引擎:1.3B 体积极易集成,NPC 毫秒级响应, 且不抢占核心渲染资源。
·AI 一对一外教:支持 15 种语言, 实时将音频转化为生动的教学画面。
来源:互联网


