
当前,金融机构在知识管理实践中普遍面临」存不全、找不准、用不对」三大核心痛点。
一、概述
(一)背景
当前,金融机构在知识管理实践中普遍面临」存不全、找不准、用不对」三大核心痛点。为应对这些挑战,国元证券通过构建「AI 知识中心+分布式数据底座」一体化平台,整合多模态知识资源,实现知识的统一纳管、智能检索与精准问答,助力业务从经验驱动向知识驱动转型。在金融行业数字化转型进入深水区的背景下,该平台基于国产化技术路线,实现从芯片、服务器、操作系统到数据库的自主可控,满足国家对金融安全与科技自立自强的战略要求。其中,分布式数据底座作为核心基础设施,采用原生分布式架构,为海量知识数据提供高可靠、高并发的存储与计算能力,确保平台在复杂业务场景下的稳定运行与弹性扩展。
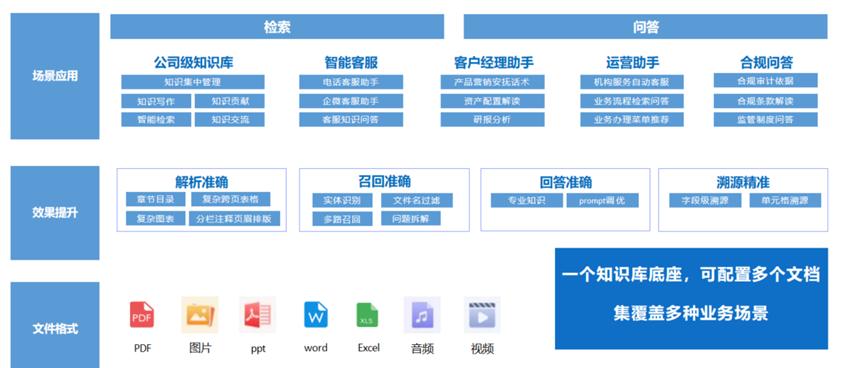
(二)应用场景
平台覆盖投顾问答、合规审计、人力信息、公司流程、运营支持等多个业务环节,服务于业务部门、管理层及金融科技团队等多元用户群体。这些场景均依赖于数据底座对多模态知识资源的统一存储与快速检索能力,保障了业务响应的实时性与准确性。
二、建设目标与关键能力
(一)解决问题
整合分散知识资源:实现百万级知识条目统一管理;依托分布式数据底座的水平扩展能力,可线性提升存储容量与并发处理性能,从容应对未来数据增长。
提升问答准确率:支持复杂表格、长图、跨页文档等高难度内容的精准解析与溯源。
杜绝信息滞后:实现知识实时同步与版本控制;数据底座的多副本机制与强一致性协议,确保了知识更新的实时同步与数据一致性。
构建知识闭环机制:解决传统知识库「静态化」问题,通过用户反馈持续优化问答效果。
满足国产化合规要求:核心软硬件实现国产化替代,通过权威认证筑牢数据安全与合规防线。数据底座全面适配国产芯片与操作系统,并通过分布式数据库的透明加密、细粒度审计等特性,满足金融级数据安全标准。
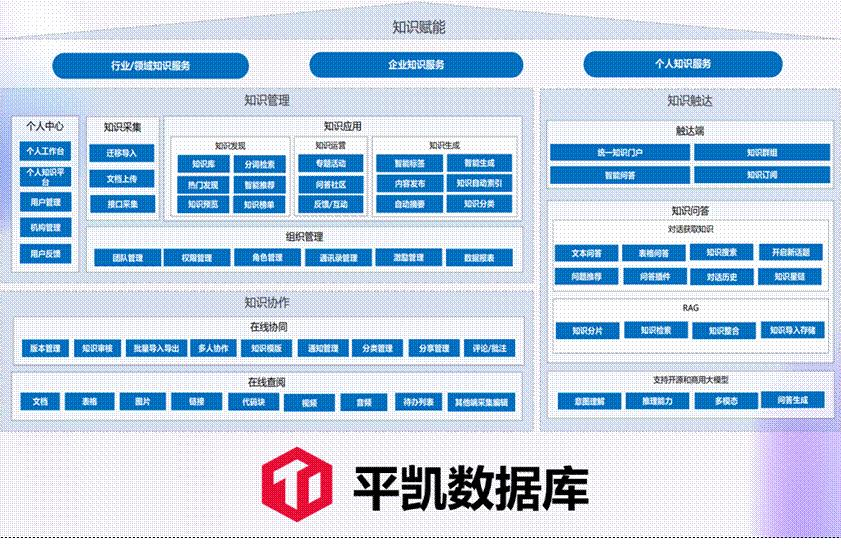
(二)主要业务功能
平台核心功能包括知识库分类管理、权限管控、文档预处理与切分、RAG 增强问答、多轮对话、溯源定位、文章写作辅助等。
(三)应用特点
集成 RAG+DeepSeek 深度思考模式,支持 5 轮上下文问答。
具备复杂文档解析能力,涵盖 Word、PDF、扫描件、Excel 等格式。
支持字段级溯源与实时跳转,确保答案可信、审计可溯。
依托分布式数据库,具备高并发处理能力,支持千级 QPS,毫秒级检索响应;该分布式数据库采用原生分布式架构,支持在线横向扩展,可在业务高峰期自动负载均衡,保障性能线性增长。
采用「模块化 RAG 架构」,将解析、切分、检索、生成等环节解耦,便于分阶段优化和组件替换,支持快速适配 DeepSeek、通义千问等主流国产大模型。
(四)应用效果
问答准确率显著提升,溯源覆盖率达 100%。
知识检索效率提升至秒级,支持百万级知识条目管理;数据底座的分布式存储与索引机制,使检索性能随节点规模增加而近线性提升,充分满足大规模知识库的扩展需求。
系统在高并发场景下稳定运行,满足全员早会等高强度访问需求。
有效降低因信息滞后或失真导致的业务决策风险,助力合规与运营效率双提升。数据底座提供的数据强一致性保障,从根源上杜绝了因数据同步延迟导致的信息失真问题。
三、平台架构与关键技术
平台整体采用分布式与微服务化的部署架构,能够满足高并发访问、海量数据存储、快速检索以及智能化问答的需求。架构从上到下分为用户访问层、应用服务层、智能处理层与数据存储层,基于国产化技术体系构建,从芯片、操作系统到数据库实现自主可控。其中,数据存储层作为平台的基石,承载了所有结构化与非结构化知识数据,其性能与可靠性直接影响上层应用的体验与稳定性。
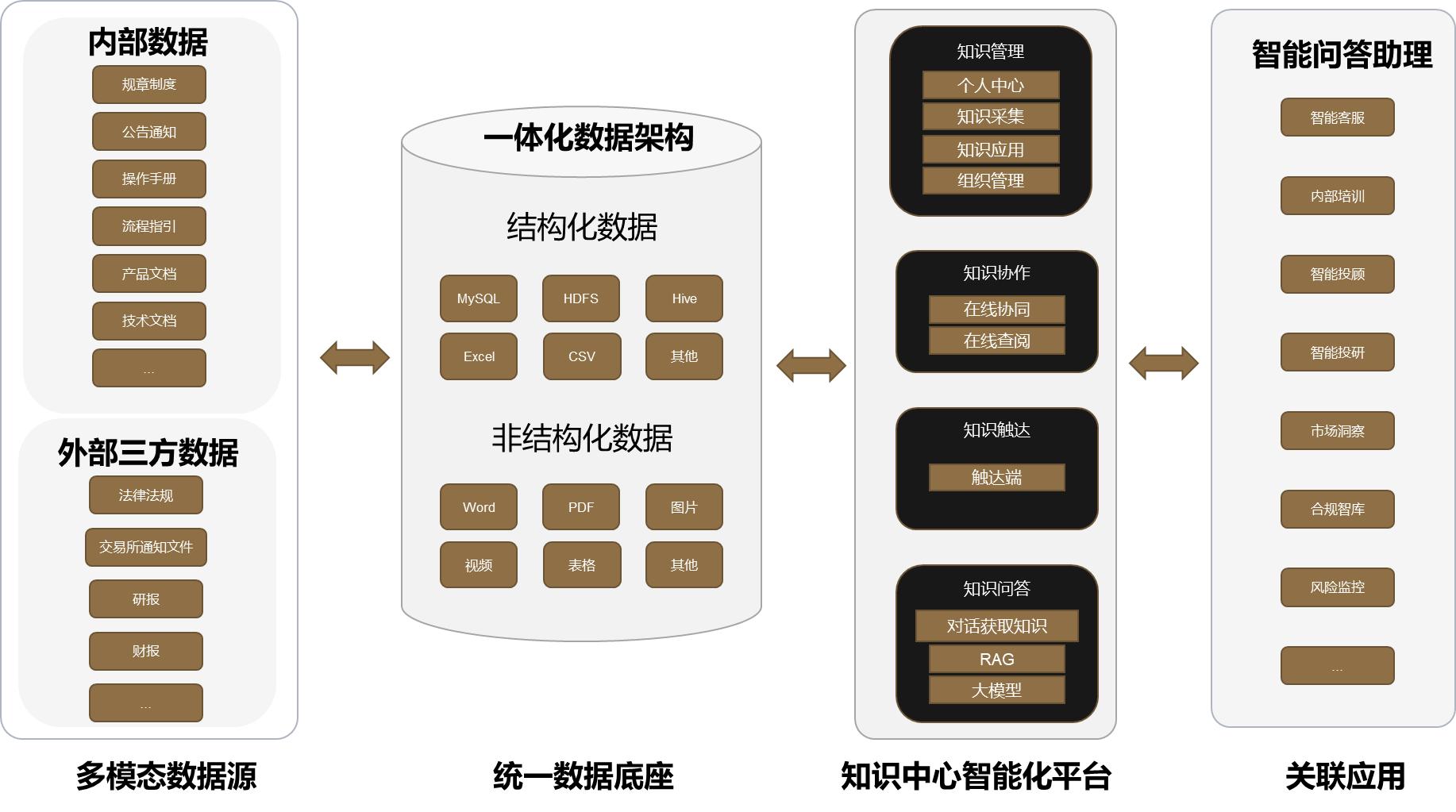
用户访问层:系统支持通过 Web 浏览器访问前端页面,进行知识内容的录入、问答和管理。前端请求通过网关统一转发至应用服务层,保证了系统安全性与可扩展性。终端支持手机端与 PC 端同步使用,满足移动办公需求。
应用服务层:主要包括知识库应用服务、检索与问答服务以及在线文档处理等模块。检索问答服务基于 RAG 框架实现,将向量检索与大模型能力结合,确保用户能够获得精准且上下文相关的回答。OCR 服务实现图像文字识别,保证文档的多格式解析能力。该层还集成了 AI 工作流框架,实现业务流程自动化与智能化。
智能处理层:系统集成了 DeepSeek 等大模型 AI 能力,能够处理复杂的自然语言理解与生成任务,并与外部知识源进行对接,持续提升知识库的覆盖度和准确性。参考政务领域的实践经验,系统支持「文字+语音+图像」全模态能力底座,深化 AI 与业务场景的融合应用。
数据存储层:基于国产化分布式数据库集群保证核心业务数据的强一致性与高可用。该层内置多层次安全防护体系,包括数据传输与存储加密、细粒度权限控制与角色分离、完整操作日志审计追踪、敏感字段脱敏处理等功能,满足等保三级及以上要求。分布式数据库集群采用多副本强同步复制技术,支持自动故障转移与在线扩容,确保 RPO=0、RTO<30 秒的高可用能力;同时,通过智能索引与分布式执行引擎,实现复杂查询的毫秒级响应。数据底座还提供了统一的访问接口,屏蔽底层存储差异,使上层应用可以像使用单一数据库一样访问分布式数据,极大简化了开发与运维。
四、建设实施路径
(一)关键技术选择与突破
针对金融文档格式复杂、RAG 效果受多环节影响、国产化替代要求高等难点,平台采取以下破解思路:
采用「模块化 RAG 架构」,将解析、切分、检索、生成等环节解耦,便于分阶段优化和组件替换。
在 OCR 与文档解析层,引入自研+多引擎融合策略,应对扫描件倾斜、印章遮挡等噪声场景。
向量模型选择上,结合通用模型与金融语料微调,提升语义相似度判断准确性。
数据库层面采用基于原生分布式架构的平凯数据库,支持海量知识条目与高并发查询。该数据库深度适配国产硬件生态,通过分布式事务与多级存储混合部署,在保证数据强一致性的同时,实现了存储成本与访问性能的最佳平衡。
(二)软硬件资源配置
针对知识库规模增长快、GPU 推理资源昂贵、国产硬件生态复杂等挑战,平台构建「分级存储+弹性计算」架构,热知识采用 SSD+分布式数据库,冷知识归档至分布式文件存储;推理服务部署时,采用动态批处理与模型量化技术,提升 GPU 利用率;预置性能基线(如百页 PDF 解析<10 秒,问答响应<3 秒)作为硬件选型与扩容依据;通过虚拟化容器部署,实现动态权限控制、交互轨迹存证等安全机制,确保「数据不出域、操作全留痕」。数据底座支持存储与计算资源的独立扩展,可根据业务负载灵活调整,在保障性能的同时降低总体拥有成本。
(三)系统集成与调试
针对与 OA、档案系统等已有平台集成时接口不统一、知识回流机制缺失等问题,平台制定《知识接入标准规范》,明确格式、权限、元数据要求,提供适配器模板降低对接成本;设计「问答-反馈-更新」闭环流程,用户可对答案标注「是否有用」,数据回流至知识运营端,用于优化切分策略与排序模型;在集成测试阶段,构建涵盖典型业务场景的「端到端用例库」,验证系统在真实环境中的稳定性与一致性。数据底座提供的标准化数据接口与适配器,有效降低了与异构系统的集成复杂度,保障了数据迁移的平滑与高效。
(四)测试验收机制
针对 AI 问答效果难以量化评判、高并发场景性能验证困难等问题,平台构建「问答评测集」,涵盖单轮/多轮/表格/长图/拒答等典型场景,设定准确率、召回率、溯源率等量化指标;引入「人工评测+自动化比对」机制,对输出内容进行采样审核与基线对比;验收时验证系统在早会等高并发场景下的性能表现(如千级 QPS,P95 响应时间<2 秒);增加国产化适配性测试,验证系统在国产芯片、操作系统、数据库环境下的兼容性与稳定性。
(五)组织管理与运营保障
针对系统上线后缺乏运营、业务部门参与不足等问题,平台设立「知识运营专员」岗位,负责知识入库审核、专题构建、效果反馈收集;推行「谁产生、谁维护」的知识责任制,并将知识贡献纳入部门考核;项目初期即组建由业务代表、AI 算法、数据工程、合规风控组成的虚拟团队,共同制定知识分类、权限策略与效果标准;诚邀监管部门、业务部门参与知识共建、场景共研;建立国产化技术培训机制,提升团队对国产软硬件的运维能力。
五、核心优势
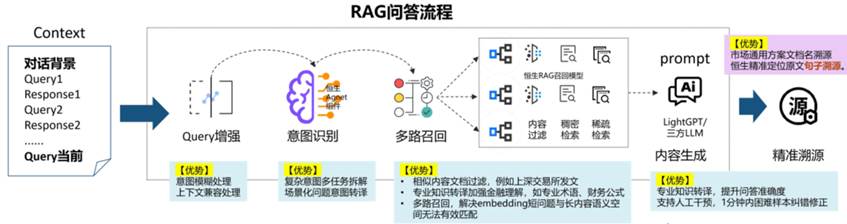
(一)全栈式 RAG 引擎
技术突破:
构建了面向金融领域的全链路优化 RAG(检索增强生成)引擎,有效降低通用大模型在专业领域可能出现的「幻觉」问题,并实现答案溯源。
实践指标:
复杂金融文档解析:自研 OCR 与文档解析构件,在测试中对扫描件(模糊、倾斜、印章遮挡)的文字还原准确率达到 98% 以上,对 Excel 跨页表格、合并单元格的结构解析与内容提取准确率超过 95%。
精准溯源技术:实现了答案到原文的字段级溯源,支持点击后在 2 秒内定位并高亮原文,使 AI 答案的可验证率达到 100%。
金融语义检索优化:通过金融语料微调的 Embedding 模型与混合检索策略,在万级知识库的测试中,问答相关段落召回率达到 96% 以上,优于传统关键词检索(约 60%)和通用向量模型(约 85%)。
(二)创新的数据架构
技术突破:
利用平凯数据库的多模一体化能力,替代传统 RAG 方案中独立的向量数据库,实现结构化元数据与非结构化向量数据的统一存储与联合查询。
实践成效:
架构简化:减少核心数据组件,使系统架构复杂度降低约 30%,运维成本与数据同步风险随之下降。
性能表现:借助平凯数据库的分布式计算与弹性扩展能力,在测试环境中支持百万级向量数据的毫秒级检索,并在每秒千级并发(QPS)场景下,保持 P95 响应时间小于 3 秒的稳定性。
数据一致性:实现了知识元数据、权限信息与向量数据之间的强一致性,避免了多数据库架构下的数据延迟与不一致风险,保障合规审计的严谨性。
(三)面向场景的 AI 能力
技术突破:
将 AI 能力封装为可解决具体业务问题的「场景化技能」,而非通用的问答接口,提升业务适配效率。
实践指标:
深度思考模式:针对复杂业务问题(如「分析某政策对债券市场的影响」),模型可自动进行问题拆解、多轮检索与综合推理,测试表明复杂问题的解答准确率相较于单轮问答提升 25% 以上。
基于 RAG 的文章写作:可根据主题自动生成大纲并检索相关内容,辅助生成投研报告、合规分析初稿,内容创作效率提升约 50%。
80+金融专属任务:预置覆盖投研、合规、运营等场景的专用任务模型,开箱即用,业务场景适配周期缩短 70%。
(四)企业级全栈应用
技术突破:
提供从底层数据、AI 中台到上层应用的全栈式、可演进的技术底座,支持知识的持续运营与价值挖掘。
实践成效:
端到端知识闭环:形成从知识接入、自动化处理、智能应用(问答/写作)到用户反馈优化的完整闭环,支持知识库的持续更新迭代。
组件化与开放输出:核心能力(如问答、检索)可通过 API 被其他业务系统(如 OA、CRM)调用,集成对接周期小于 5 人日,实现知识能力的复用。
企业级治理能力:支持 100% 操作行为审计日志、字段级权限控制与多版本管理,满足金融级合规与安全要求。
六、展望
展望未来,国元证券将持续深化国产化分布式数据底座与 AI 技术的融合,进一步挖掘其应用潜力。一方面,依托数据底座的高扩展性与强一致性,平台将向「自感知、自优化、自决策」的智慧知识中心演进,实现知识资产的主动运营与智能洞察;另一方面,数据底座与 AI 的协同进化将形成数据与模型的闭环优化——数据底座为模型训练提供高质量、低延时的数据供给,而模型推理结果反哺数据治理,持续提升知识服务的精准度与时效性。最终,基于国产化分布式数据底座的智能知识中心将成为企业数字化转型的核心引擎,为业务创新与合规运营提供坚实支撑。
来源:互联网


