它试图回答另一个问题,有没有可能通过算法范式创新,从而绕开数据、乃至算力和能源的限制?

作者|Li Yuan
5 月 25 日,极客公园获悉,具身智能公司具脑磐石完成新一轮亿元级融资,本轮融资由具备深厚类脑与具身产业背景的顶尖产业资本领投,老股东及多家顶尖基金复投和跟投,多维资本担任独家财务顾问。同时,更新一轮融资也在同步交割中。
具脑磐石成立于 2025 年,是具身智能赛道里一家很新的公司。但从一开始,它选择的就不是去年最热闹的 VLA 路线,也不只是把「世界模型」作为一个新概念贴到机器人身上。
这家公司从成立之初,就把技术主线放在了认知层的方向:以类脑智能为底层范式,以 JEPA 同向的抽象表征学习为关键路径,构建面向真实物理世界的认知世界模型(Cognitive World Model)。
这个选择,让具脑磐石在今天显得更有参照意义。
2026 年,Yann LeCun 离开 Meta 后创立 AMI Labs,将 JEPA、世界模型、推理与规划重新推到下一代 AI 范式讨论的中心。在尚未推出公开模型前,AMI Labs 的估值已达到 35 亿美元。某种意义上,LeCun 的再次创业,让一条此前偏前沿、偏少数派的技术路线,被更大范围的产业和资本市场看见。
而在 AMI Labs 之前,具脑磐石已经把这条当时很多人还看不懂的路线,设定为公司的主线。
具脑磐石创始人朱森华博士曾任华为云 AI 算法创新 Lab 主任,在华为期间,他曾主导或参与 AI 脑科学云平台、盘古具身大模型、深圳全球具身智能产业创新中心等项目,也参与过华为顶尖 AI 人才选拔,担任过「天才少年」面试官。朱森华带领团队自 2020 年起,就在类脑 AI、世界模型上进行了技术探索和应用验证。
过去两年,具身智能行业的大部分讨论都围绕一个问题展开:机器人数据还不够多。具身智能希望复刻大语言模型的经验,通过堆砌大量的真机数据、仿真数据和异构数据,训练出能够泛化到更多任务的机器人模型。
但朱森华想追问的是,数据当然重要,如果算法范式本身没有变化,只是继续扩大数据和算力,机器人真的能获得接近人类的智能能力吗?
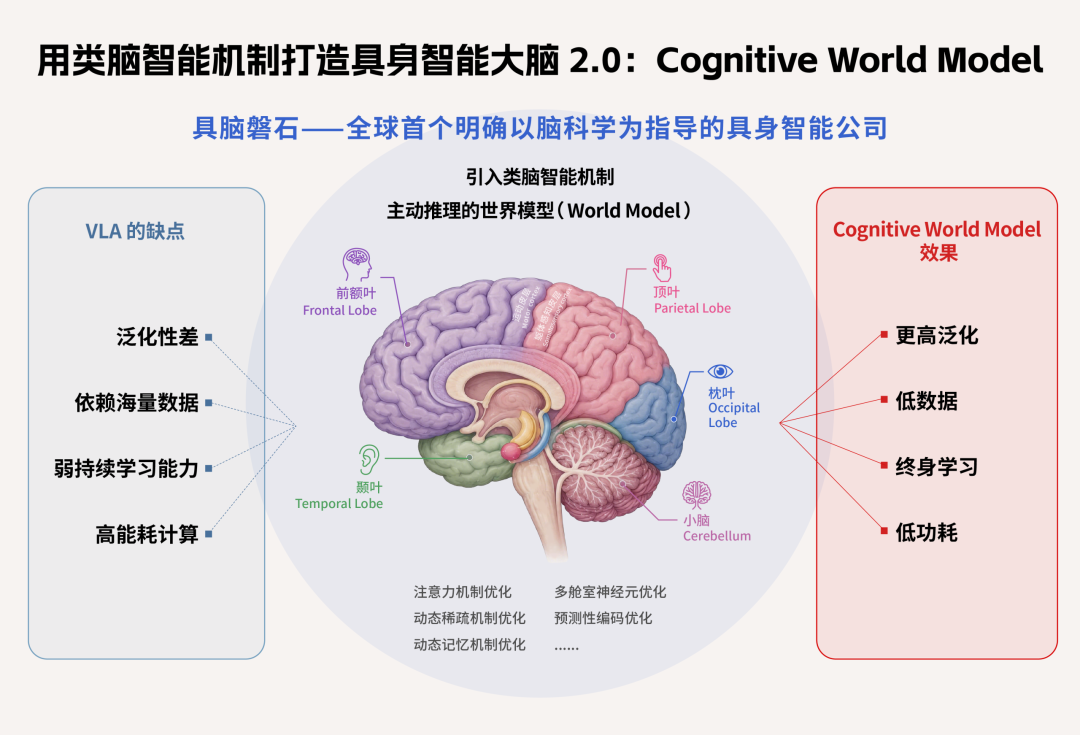
在他看来,今天以大模型和 VLA 为代表的具身智能路线,真正卡住的不是单点能力,而是四个结构性问题:需要大量数据才能学习,换一个场景就容易失效,训练完成后难以持续更新,还要依赖很高的计算和能源成本。
在接受极客公园采访时,朱森华的观点很直接:今天具身智能的问题,很多人并不是不知道,而是知道之后没有办法真正「立」出一套新东西。因为一旦把旧范式的问题讲透,就必须回答下一条路是什么。
具脑磐石想回答的,正是这个问题。
在公司看来,机器人需要的不只是更大的动作模型,而是一个能在物理世界中形成抽象表征、长期记忆、主动推理和持续学习能力的「大脑」。
人脑并不依赖巨大的算力和海量数据,才能在复杂环境中行动。比如人过马路时,并不会精确计算每辆车的速度、每个行人的轨迹和红绿灯的秒数,但仍然可以基于对环境的粗粒度理解,对未来状态进行推理和预判:什么时候观察、什么时候等待、什么时候通过。只有仿人脑认知的路线,可以实现低数据、高泛化、终身学习和低功耗。
具脑磐石这轮融资的看点,在于一条更少数派的具身智能路线正在被资本押注:当行业还在争论怎样获得足够多的数据时,它试图回答另一个问题,有没有可能通过算法范式创新,从而绕开数据、乃至算力和能源的限制?
01
以JEPA架构为核心的模型结构
要理解具脑磐石的技术路线,需要先把「世界模型」这个词拆开。
过去半年,世界模型几乎成了具身智能里最热的概念之一。但它其实不是一条单一技术路线,而是一个很宽的技术体系集合。朱森华在采访中中把它拆成了自下而上的几个层级:空间智能解决「视觉真实」,视频生成试图解决「物理真实」,学习型仿真解决「交互真实」,再往上,才是以 JEPA 为代表的「抽象学习」。
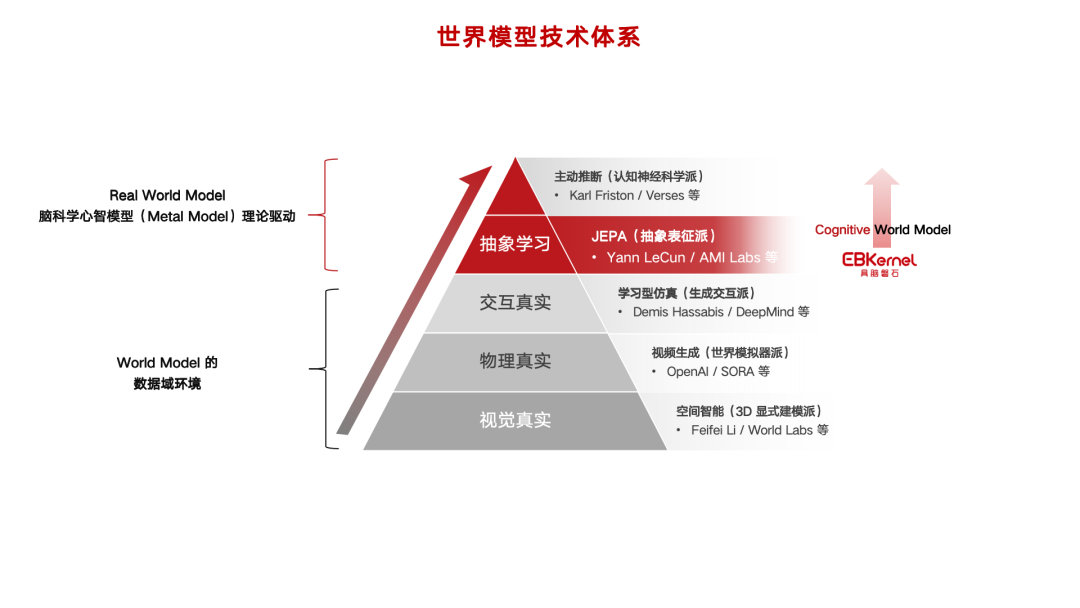
也就是说,很多人今天谈到世界模型,想到的是一个更逼真的模拟器:能不能生成足够真实的环境,能不能预测下一帧画面,能不能在虚拟世界里复现物理规律。
但在具脑磐石看来,这些还没有真正进入机器人「认知世界」的那一层。它押注的是 JEPA。
JEPA,全称 Joint Embedding Predictive Architecture,联合嵌入预测架构。和很多生成式世界模型不同,JEPA 的核心不是生成下一帧画面,而是在隐空间里预测状态变化。它不要求模型逐像素复原世界,而是让模型学习世界背后的结构和关系。
举一个粗略的例子,同样是学习开车,一类世界模型可能更像是在生成「车开过去之后,下一帧画面是什么」:路面、车道线、前车位置、光影变化都要尽可能逼真。但 JEPA 更关心的是另一件事:当前道路状态、前车运动、驾驶动作之间的抽象关系是什么;踩刹车、打方向、加速之后,世界状态会怎样变化。
这些状态不需要以像素的方式被复原,而是可以被压缩到一个更高层的表征里。
这也是为什么 JEPA 会被认为更接近人脑的认知方式。人脑并不是靠逐像素复原世界来理解世界和推理规划。人过马路、开车、拿起一个杯子,依赖的都不是对所有视觉细节的穷举,而是一个更压缩、更抽象的心智模型:哪些信息重要,哪些变化会带来风险,下一步动作可能导致什么结果。
JEPA 解决的了抽象表征和泛化问题。具脑磐石想做的,是把这套抽象表征学习能力放进具身智能系统里。
它提出的 Cognitive World Model,即认知世界模型,是希望在 JEPA 的表征预测能力上,继续引入脑科学里的注意力机制、动态记忆机制、预测编码和稀疏计算机制,最终让机器人具备四个能力:低数据、高泛化、终身学习、低功耗。
朱森华解释这件事时,会反复回到人脑的机制。
比如,人睁开眼睛时,视网膜每时每刻都在接收环境数据。如果把它简单理解成摄像头,人脑面对的是连续不断的高维输入。但人脑并不会把所有像素以同等权重处理一遍。它有非常高效的前置注意力机制,会先筛选哪些信息重要,再进入后续理解和决策。
这对应到具脑磐石的算法方向,就是类脑感知编解码:先在输入侧降低无效数据量,而不是把所有数据都喂进大模型之后再寻找特征。
多模态也是类似逻辑。今天很多 VLA 工作,是把视觉、语言、动作等模态向大语言模型对齐。但人类并不需要先学会语言,才能把听觉、视觉、触觉和动作经验统合起来。一个小孩还不会完整说话时,也能完成大量感知、模仿和行动学习。朱森华认为,这背后有认知神经科学可以解释的多模态融合机制,也可以被转化成算法。
终身学习则对应大脑的突触可塑性。人学会骑车之后,再学开车,并不会因此忘掉骑车。人的记忆也不是所有信息都永久存储,而是有刷新、更新、临时记忆和长期记忆之间的机制。朱森华认为,这些脑科学机制不需要被还原论式地完整复刻,但可以像飞机学习鸟类飞行一样,抽象出背后的「空气动力学」。
在这样的架构下,机器人仍然需要数据,也仍然要解决工业、康养、零售、家庭里的真实任务。
但朱森华认为,如果模型学到的是更高层的表征,而不是被迫穷举每一种场景细节,所有数据都可以更有效地进入同一个认知框架里,任务也会变得更容易学习和迁移。
他提到,团队在既有 Open X-Embodiment 一类基准数据集上,曾看到过用约 1/10 数据完成同等技能学习的阶段性结果。
这个数字仍然需要放在具体任务和测试条件里理解,但它指向了具脑磐石最核心的判断:具身智能的问题未必只能靠更大的数据集解决,也可能要从模型架构本身重新打开。
02
不只做模型,也要把模型推到现场
具脑磐石选择的路线足够前沿,但它并不想把自己做成一家只停留在实验室里的模型公司。
这和朱森华对创业时机的判断有关。在他看来,一家公司要真正出来做这件事,至少要同时准备好三件事:技术主张是不是清楚,商业化策略是不是清楚,以及有没有一支能同时支撑研发和商业落地的团队。具脑磐石不是在成立之后再找方向,而是在这三件事都相对 ready 之后,才把这条路线公司化。
因此,具脑磐石并不希望等待这一前沿架构完全收敛后才开始进行商业化。
朱森华本人是一个复合型创始人。他有着 AI、脑科学和具身系统工程的交叉背景。同时,他在华为期间,除了探索「今天有局限的 AI」下一跳在哪里,还同时需要判断这些创新技术未来能服务什么客户、解决什么问题。这让他不是从论文里抽象地选择类脑路线,而是在大厂体系内经历过从技术预判、系统架构到产业验证的完整链条。
他还提到,具脑磐石的核心团队也不是临时拼起来的。公司的联创和合伙人团队,有的是他在华为的原班同事,有的是从 2021 年开始一起把 AI 和脑科学带入具身智能机器人业务的外部伙伴。这些人过去多年已经在技术研发、算法工程、供应链、商业化、运营、海外拓展上有过磨合。其商业化团队曾在工业和商用场景实现机器人的万台级规模部署和亿元级年收入。
这决定了具脑磐石的商业化策略是「成熟一部分,转化一部分」。
朱森华把它称为真实客户场景对技术闭环的牵引,更直接的说法叫「沿途下蛋」:长期目标是类脑具身智能和 Cognitive World Model,但阶段性会释放可落地模块,形成数据闭环与现金回流。
从披露的信息看,具脑磐石目前已在具身感知交互、规划、移动导航、操作及群体具身等方向完成多项系统级技术验证,正在把认知世界模型从算法框架推进到真实机器人系统。今年以来,公司已经与国内汽车产业上下游多家龙头公司展开场景落地合作,海外市场也携手日本合作伙伴完成了首个工业场景 PoC 验证。
它选择场景时有三个标准:客户是否真的有付费意愿,场景是否具备规模化复制可能,以及这个场景能不能反过来牵引核心技术发展。换句话说,具脑磐石不想做一次性定制项目,而是希望在工业、康养、零售等方向里,找到既能形成商业回流,又能沉淀通用能力的任务场景。
这三个标准背后,还有一个更实际的商业判断:国内和海外客户的商业逻辑不一样。朱森华认为,国内客户更多会考虑机器人能不能完全替代人、ROI 能不能算得过来。但在当前阶段,一套几十万、上百万的具身机器人解决方案,未必能立刻证明比人更便宜、更高效。而在海外市场,尤其日韩、欧美为代表的发达国家,则面临更直接的劳动力短缺问题。即便机器人暂时还达不到完全替代人的能力,只要能在局部场景补充劳动力缺口,客户也可能为此付费。这解释了为什么具脑磐石会同时把出海作为公司战略之一。
朱森华在采访中也强调,今天不同技术路线最终面对的客户问题并没有本质差别。工业里要解决的还是巡检、搬运、码垛、上下料、装配等;康养和零售里要解决的还是交互、服务和效率。区别不在于不同客户提出的场景各异需求,而在于完成同一个任务时,模型需要多少数据,交付需要多长周期,迁移到下一个场景的成本有多高,以及系统能不能长期稳定运行。
具脑磐石公司目前总部在上海,现阶段团队已有几十人、集中在上海办公。对于一家刚成立不久的公司来说,这种配置也对应了它的阶段:先集中投入把核心研发、场景验证和商业化闭环跑起来,而不是一开始就拉开一张过大的研发摊子。
03
在前沿找路
具脑磐石这家公司有一个很鲜明的气质:它不是沿着行业最热的词往前走,而是一直试图把问题拉回到「AI 到底要往哪里去」。
这和朱森华本人的表达方式有关。他在采访中很少把问题只讲成某个模型、某个指标、某个客户,而是习惯从技术史和范式变化的角度看具身智能。
他提出,现有的旧范式的问题大家都知道:大模型有幻觉,VLA 泛化有限,机器人数据很贵,端到端模型部署成本高,持续学习困难,这些问题从业者大多知道。但是因为很多人认为没有更好的框架来解决这个问题,就回避这个问题。
朱森华有一个说法很能概括他的判断:今天 AI 的很多进展仍然是「有多少人工,才有多少智能」。这里的「人工」既指数据,也指工程试错。一个实验室探索出一个技巧,行业跟上;另一个团队试出一个新方法,再被吸收进来。这个过程当然能推动能力进步,但它并没有回答一个更底层的问题:智能为什么会产生,模型为什么能学习,系统为什么能在长期交互中演化。
这也是他为什么反复强调认知神经科学。
在他看来,人工智能从一开始就和人脑有关。从神经元建模、神经网络,到注意力机制,很多关键概念都来自对人脑智能的观察和抽象。今天如果 AI 要突破低数据、高泛化、终身学习和低功耗这些瓶颈,也不太可能只靠在既有 Transformer 框架 或 VLA 架构上继续堆数据、堆算力,而需要回到人类智能本身,站在第一性原理寻找可被计算化、工程化的机制。
人工智能最早的来源正是来自类脑,只是今天的大模型路线在工程上走得太快,反而让很多人忘了这些概念最初来自哪里。
朱森华把这件事放在了一个中美正在同一前沿上推进的大环境判断中。
他认为,今天的具身智能和下一代 AI 并不是一个已经有成熟路线、国内团队只要追随对标的阶段。VLA、世界模型、JEPA、主动推理都还在技术孵化期,没有任何一条路线已经被证明是终局。在这个阶段,中国公司不是只能等美国先走出标准答案,而是有机会和国际顶尖团队在同一前沿探索。
在与投资人交流里也能看出这种张力。朱森华提到,在 LeCun 举起 AMI Labs 这面旗帜之前,投资人会习惯性追问「市场上对标你的公司是谁」。这背后是一种路径依赖:美国先有一个成熟对象,中国再找对标。但他认为,今天 AI 和具身智能已经不是一个有成熟技术可抄、可追随的阶段,而是中美同时处在技术孵化和路线培育期。投资人要判断的不再只是「像不像某个美国公司」,而是方向是否正确,以及人和事是否匹配。
当然,这条路并不容易。朱森华也承认,类脑智能驱动的具身智能 2.0 难在技术选择,难在技术宣讲,也难在人才密度。它需要认知科学、神经科学、人工智能、机器人学等多学科交叉,而这类人才本身就比传统计算机科学人才稀缺得多。它也需要更长时间的技术验证,不像跟随成熟框架那样容易获得短期共识。
朱森华讲到:「今天没有一个技术范式可以明确告诉你,我就是未来,不需要改进了。在我看来,从方法论、哲学论角度上来说,第一重要的事情是你选的方向是否正确。」